
Hyperscale Advantages (AWS, Azure, and Google Cloud)
Summary
The hyperscalers' elevated AI CapEx programs should earn attractive returns on invested capital assuming underlying AI demand continues to outpace supply. Bottom-up, neocloud breakeven economics (~$1.55/hr H100, ~12% unlevered IRR) should establish the industry’s base return on capital in a balanced market, while hyperscaler advantages – procurement discounts, pricing power, custom silicon, frontier lab revenue share agreements, and traditional compute pull-through – point to "high-teens+" project-level returns.
Critically, co-existent bottlenecks (NIMBYism, power, electrical equipment, labor) will likely prevent data center capacity from coming online at the consensus forecasted pace, allowing the hyperscalers to sustain GPU-rental pricing power well beyond current contracted periods – pushing realized returns for hyperscalers meaningfully above “balanced market” levels in the near-term.
Competitive positioning further supports attractive long-term returns: data gravity, security/governance requirements, enterprise discount program (EDP) burn-down dynamics, and system-integrator (SI) ecosystem entrenchment creates durable switching costs that insulate hyperscalers from neocloud price competition and frontier lab disintermediation.
Top-down, I estimate AWS's AI-specific invested capital is generating a ~12% ROIC (8%–15%) as of year end 2025, which is healthy for a business still in its infancy. I focus on AWS because it is the only hyperscaler whose AI-related CapEx is cleanly disaggregable from other business lines, and we recently received commentary on AWS’s AI revenue from the 2025 shareholder letter. Google and Microsoft are harder to decompose given less granular disclosures, however, I end by commenting on factors affecting the prospective ROICs for each of the “Big 3.”
Situational Overview
After significantly higher than expected 2026 CapEx guides from Amazon and Google, it’s worth revisiting the question “what level of confidence do we have that the hyperscalers are earning attractive ROIs on this spend?”
To start, let’s lay out the two potential bear cases:
Bear Case #1
“This is an over investment – and as production level AI use cases fail to scale, all of the hyperscalers are going to waste significant amounts of cashflow chasing demand that will fail to materialize.”
I’m unconcerned with this bear case (at the current valuation levels) for the hyperscalers for two primary reasons:
First, as laid out in my recent memo (“Token Demand Inflection…”), my conviction in token demand/consumption continues to grow. Last December, the introduction of OpenAI’s o1 reasoning model laid the groundwork for a step-function change in total token consumption due to the compute intensity of chain-of-thought reasoning. In December 2025/January 2026, the rapid advancements in Claude Code/Codex (command line interface & computer use coding tools), Claude Cowork (effectively a chat-based version of Claude Code), Claude for Excel/PowerPoint/Word, and OpenAI-style agentic harnesses led me to believe we are in the process of witnessing another step-function change in compute demand.
Second, if the hyperscalers are over investing to some degree, they should be able to scale over these investments in the coming years by significantly reducing capital intensity. We saw Amazon do exactly this after they over-estimated demand during COVID for the retail side of the business.
I estimate Amazon will produce ~$200B of CFO on an NTM basis (blending ~$185B in FY2026E and ~$230B in FY2027E). If we assume a more normalized level of capital intensity for AWS (28-30% historically) on ~$183B of NTM AWS revenue, we get normalized AWS CapEx of ~$53B. Assuming ~$36B of CapEx for retail, and excluding ~$26B of SBC, this framework would imply ~$85B of look-through economic UFCF against a ~$2.55T enterprise value — roughly a 30x NTM multiple. This is presented as a sensitivity exercise to frame the downside scenario, not as a price target or recommendation. Actual outcomes depend on many variables outside the author's forecast, including competitive dynamics, regulatory changes, and capital-allocation decisions.
Again, I’ll reiterate that I’m in the “AI/token demand is going to continue increasing rapidly” camp, however, I think the above point frames the downside case with respect to potential over investment.
Bear Case #2
“The demand is real and the hyperscalers will sell all of the compute that they bring online, however, the economics of GPU-cloud are structurally worse than the economics of CPU-cloud – and putting this much capital into a structurally worse business is concerning.”
Both Dan Sundheim1 and the financial blogger Mostly Borrowed Ideas2 have made some version of this argument in recent months. In my opinion, this is the more concerning bear case, and is where I’ll concentrate the rest of this memo.
Dan Sundheim has publicly articulated a version of this bear case (Invest Like the Best, February 2026): the core concern is that while hyperscaler AI growth may actually accelerate over the next several years, the underlying business model is structurally weaker than traditional cloud because (i) the LLM customer base will likely concentrate into four to five players versus the broadly fragmented CPU-cloud base, (ii) those frontier labs are likely to insource compute once cashflow-generative, and (iii) AI workloads are materially more capital-intensive than traditional CPU workloads. Neoclouds are viewed as likely to persist — both because they are arguably better operators of GPU clusters and because Nvidia has strong incentive to keep the customer base diversified.1
To frame the conversation, I think it’s worth highlighting that while the debate around CPU vs. GPU economics tends to gravitate towards “what are the margins on GPU-cloud,” I believe this is an inappropriate way to think about the business. The KPI to judge returns is ROIC — which is determined by NOPAT margins and invested capital turnover.
ROIC = NOPAT / Sales * Sales/Invested Capital
It’s worth noting that AWS’s reported ROIC (again, the only hyperscaler we have clean number for) has been declining in recent periods due to declining invested capital turnover (even as margins have expanded).

However, the most important KPI when evaluating AWS is not ROIC, but economic value added.
EVA = (ROIC - WACC) * Invested Capital
Simply, if AWS is seeing lower returns on capital for GPU-cloud, but the returns still exceed AWS’s cost of capital and Amazon has the ability to deploy significant amounts of capital, that will generate economic value for Amazon. For Amazon (or any of the hyperscalers), to sell-off on increased CapEx guides, the market’s implication is that these capital outlays will not earn Amazon’s cost of capital.
Below I attempt to analyze the potential return on capital for hyperscaler GPU-cloud from bottom-up (unit economics), qualitative (does the competitive positioning point towards attractive returns on capital?), and top-down (reported financials to date) perspectives.
Bottom-Up Analysis
GPU-as-a-Service (GPUaaS) Project Level IRRs in a Balanced Market
To serve as an anchor point for hyperscaler GPU-cloud economics, it is worth determining what the economics need to look like for neoclouds to earn their cost of capital (with neoclouds serving as the incremental industry capacity) by renting GPUs.
CoreWeave’s (by far the most mature of the neoclouds) debt trades at a 9-10% yield-to-worst, and the business just recently issued notes at 9.75% for ~100/101. Therefore, CoreWeave’s post-tax cost of debt likely sits in the ~8% range. Its cost-of-equity on the other hand is likely in the low-to-mid teens. With a near 50/50 split between debt and equity, CoreWeave’s cost of capital likely sits in the low teens (10-13%).
Again, it’s worth noting that CoreWeave is the most mature of the neoclouds, and the less scaled players likely have even higher costs of capital (mid-teens+).
Below are my estimates for project level assumptions necessary for a neocloud like CoreWeave to earn a ~12% unlevered IRR (and ~15% blended ROIC) on 1 megawatt worth of H100s (751 GPUs).
Some of the underlying assumptions:
- H100 Servers are purchased for ~$31k/GPU (pricing is well established by industry reports)
- Servers are rented for $1.55/hour at 100% utilization (long-term take-or-pay style contracts)
- Servers (including networking equipment) are depreciated over six years
- Colocation (a.k.a. rent), power costs, and other direct costs are industry standard
- SG&A overhead is ~$1.7M, or approximately ~17% of revenue (I’m making a bit of an assumption here, but I’ve heard anything from high-single digits SG&A overhead for bare metal instances to ~20% when offering managed services/software)
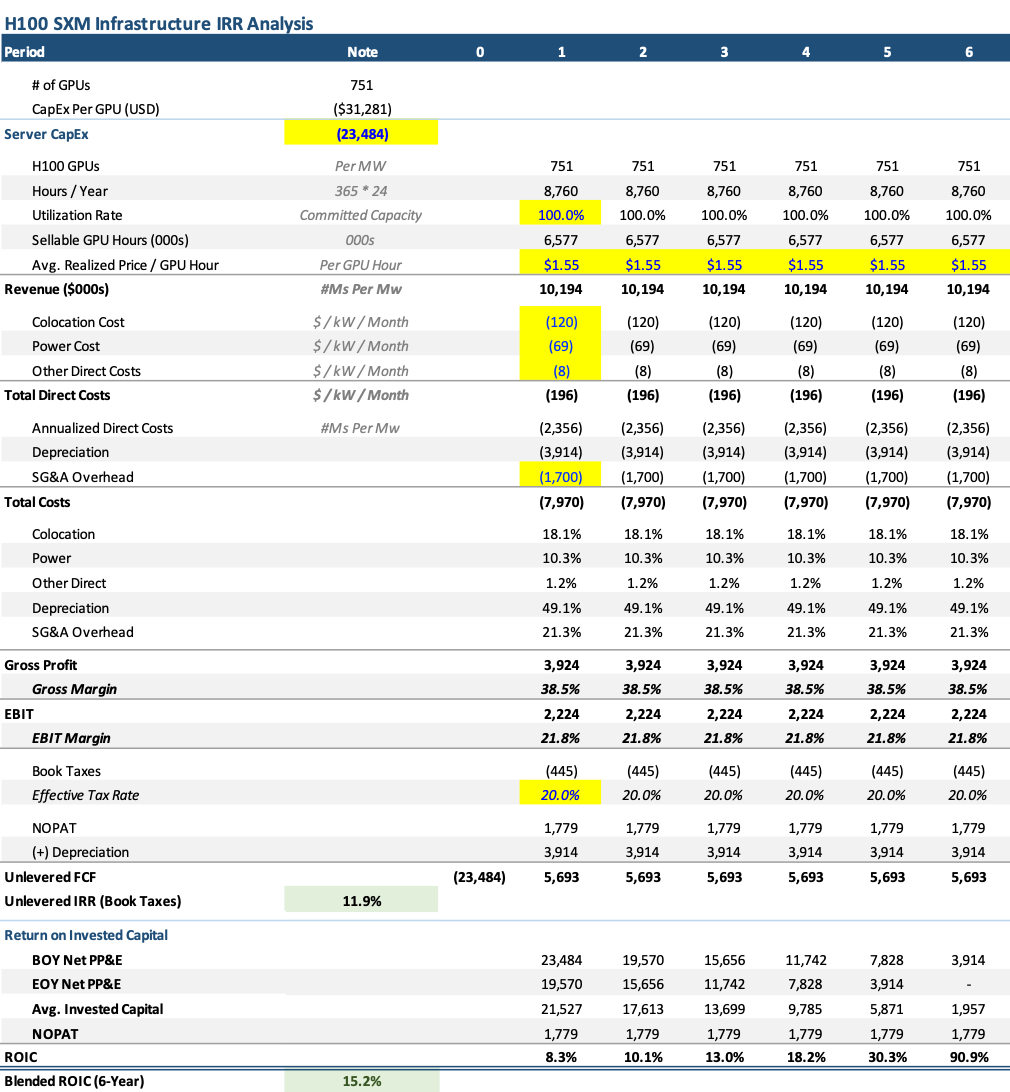
These estimates tend to align well with other industry signposts:
- Many industry participants have noted that rental revenue per MW for H100s has averaged $10-12M/MW (both Oracle and neoclouds have noted this, and the frontier labs have previously mentioned this is what they were paying to rent 1 MW of compute)
- Gross margins of ~38% align with 30-40% guidance from Oracle
- EBIT margins of ~22% align with ~25% stabilized contribution margin commentary from CoreWeave
- Other industry participants have noted that ~$1.50/hour is roughly the point at which neoclouds breakeven on H100s after adjusting for capital costs. Per my model, $1.55/hr results in a 12% IRR vs. a low-to-mid teens cost of capital for neoclouds
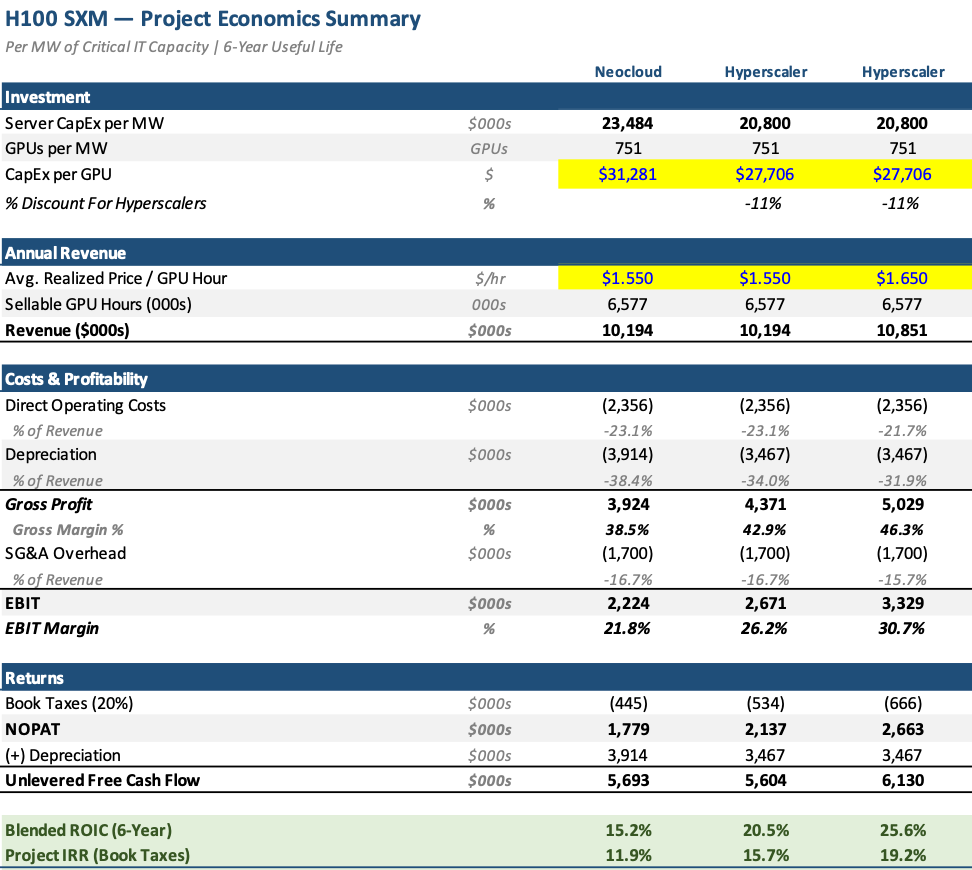
So, now that we’ve established that the above model is likely a decent project-level model for the neoclouds – and given that, in a balanced market, neoclouds (as the swing capacity) should help set industry-wide pricing – we can begin to work up towards what we think project level returns for the hyperscalers should be.
There are two major differences between the hyperscalers and the neoclouds that materially impact the economics.
First, the hyperscalers are able to purchase H100s (and other GPUs) at a discount.
Primary research suggests hyperscalers may purchase Nvidia server hardware at discounts ranging from roughly 5% up to ~30% relative to leading neoclouds, with the spread driven largely by cumulative volume.3 Industry sources indicate that while neoclouds negotiate favorable per-unit pricing relative to their scale, absolute hyperscaler purchase volumes meaningfully exceed what neoclouds can commit to.3
Industry analysis has historically indicated a hyperscaler procurement discount of roughly 11% vs. the largest neoclouds, and roughly 16% vs. less-scaled neoclouds.4
Additionally, Microsoft has publicly indicated that its negotiating position with Nvidia has improved since introducing Maia.5
The combination of scale purchasing and custom silicon alternatives allow the hyperscalers to purchase GPU servers (by far the largest cost-item for GPU-cloud) at a meaningful discount to neoclouds.
Second, the hyperscalers are able to charge higher prices (on a $/GPU-hour basis).
I’ll discuss the reasons more below, but hyperscalers are able to charge higher prices per GPU-hour due to switching costs and ease of procurement.
Ultimately, the hyperscalers are able to earn better project-level IRRs/ROICs vs. the neoclouds due to the ability to procure servers at a lower cost combined with the ability to charge slightly higher prices. The upshot? If neoclouds are earning low-teen returns on capital, hyperscalers are likely earning high-teens+ returns based on these two advantages alone.
Hyperscale ROIC “Boosts”
While both hyperscalers and neoclouds can rent out GPU capacity, the hyperscalers tend to have additional ways of monetizing AI demand that are higher margin/ROIC.
Custom AI Accelerators – Google (TPUs), Amazon (Trainium), and Microsoft (Maia) each have their own in-house AI accelerators. There are three ways that a strong custom silicon program can improve hyperscaler ROICs.
- As mentioned above, custom silicon programs introduce negotiating leverage vs. Nvidia, which can then be used to secure additional discounts.
- Second, custom silicon programs are able to bypass Nvidia’s ~70% gross margins, resulting in significantly lower capital outlays for a set amount of compute capacity. This benefits the hyperscalers for their own internal workloads. Google runs virtually all of its compute infrastructure on TPUs and Amazon mentioned on its Q4 2025 earnings call that the majority of the inference flowing through Bedrock (its LLM API gateway/endpoint) is now on Trainium.6
“Having our own hotly demanded AI chip opens up many possibilities, but perhaps none larger than the ability to lower costs for customers and secure better economics for AWS. At scale, we expect Trainium will save us tens of billions of capex dollars per year, and provide several hundred basis points of operating margin advantage versus relying on others’ chips for inference.” – Andy Jassy, 2025 Amazon Shareholder Letter7
- Third, hyperscalers can sell their compute externally to third party customers via compute or licensing deals. Both Amazon and Google have now announced large deals with Anthropic to provide compute infrastructure using TPUs and Trainium. Additionally, Google, Anthropic, and Broadcom recently announced a 3.5GW deal for TPUs where it appears that Google will put up none of the capital and receive a ~15%ish take-rate for licensing their TPU IP. This is a fantastic return on capital. Jassy also made comments in the shareholder letter indicating that they are considering similar deals (which leads me to believe a Trainium/Graviton deal such as the Google/Anthropic licensing deal is likely to be announced in the near future).7
Revenue Share Agreements – Microsoft is entitled to 20% of OpenAI’s revenue until an independent expert panel verifies AGI (as of now OpenAI is also entitled to a portion of the revenue Microsoft generates from Azure OpenAI Services and Bing). Google & Amazon receive ~10-20% of Anthropic’s revenue facilitated through their API endpoints (Vertex & Bedrock). And while we don’t yet know deal terms, there is almost certainly a revenue share agreement between OpenAI/Amazon for OpenAI Frontier and Anthropic/Microsoft for Claude over Microsoft Foundry (with the $ flowing from the frontier labs to the hyperscalers).
These revenue shares are incredibly capital efficient, as they represent incremental margin on top of already-deployed compute infrastructure — the hyperscaler has already invested the capital to serve inference, and the revenue share functions as an additional toll on enterprise token usage requiring no incremental capital outlay beyond what is already committed for GPUaaS. Lots of ink has been spilled discussing the returns on capital the hyperscalers will earn deploying compute for the frontier labs, but the capital efficiency of these revenue share agreements has received much less attention. I estimate that this partner revenue share equates to ~7% of Microsoft’s net AI revenue, ~3% of Amazon’s AI revenue, and ~1% of GCP’s AI revenue as of Q4 2025. These percentages should increase over time as enterprise penetration accelerates and the revenue makeup shifts from training to inference.
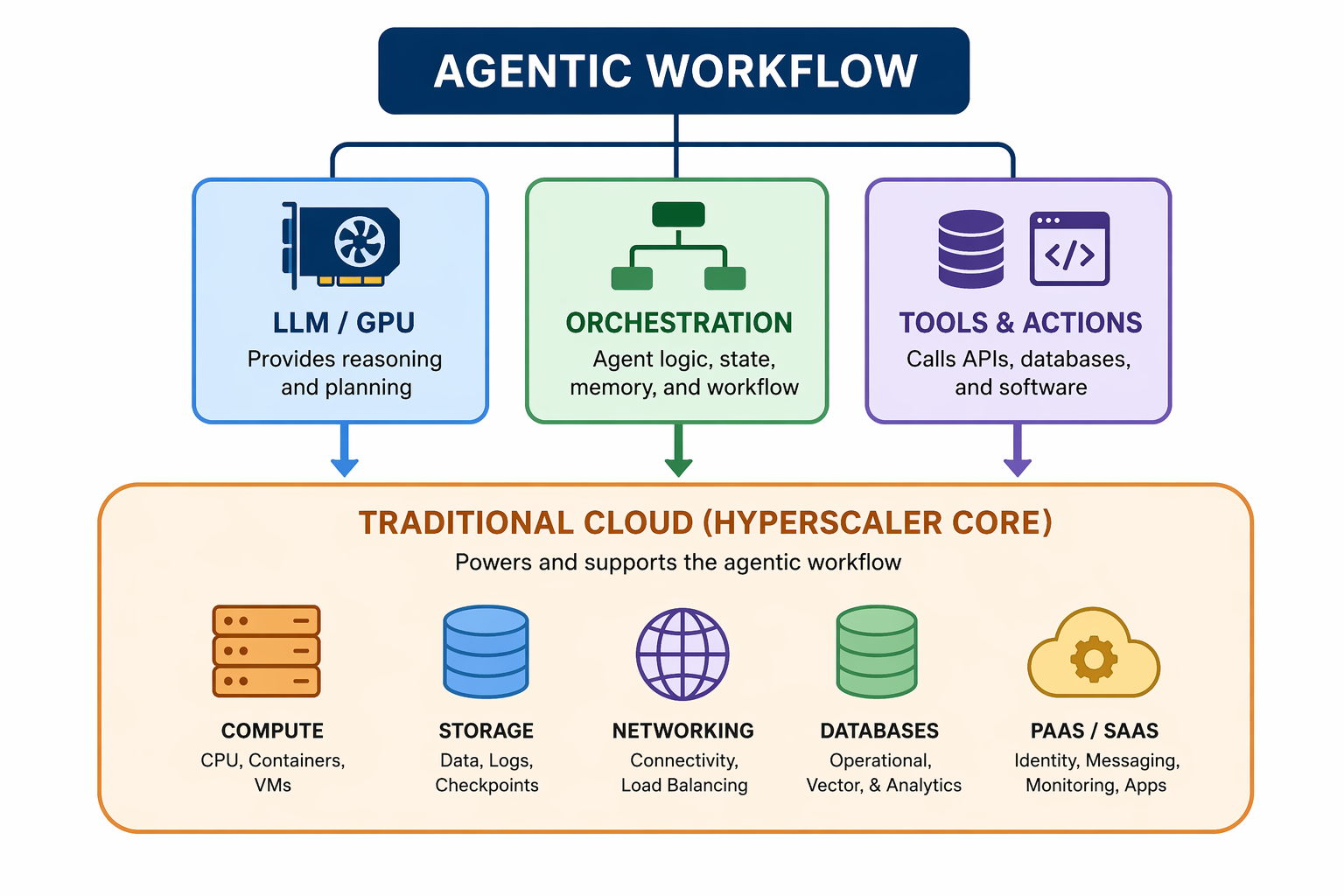
Traditional CPU Workloads – In a “chat” first world, it was easier to disaggregate CPU-cloud from GPU-cloud. However, as we move towards agentic workflows, it becomes much more difficult to draw a clear line of demarcation. While LLMs provide the reasoning engine, the rest of the workflow takes place in a traditional compute environment. An agent needs skill instructions, state & memory, the ability to call tools (such as databases and software), etc. The hyperscalers are deeply embedded in their customers' traditional compute environment and earn very attractive returns on capital in the “traditional compute environment.” Agentic workflows don’t only increase GPU compute needs, but also increase the need for all of the traditional compute, storage, networking, and PaaS/SaaS that hyperscalers have served historically.
Industry commentary from SemiAnalysis founder Dylan Patel at the Daytona Compute Conference (March 2026) suggested that part of the impetus for the recent Amazon–OpenAI deal was OpenAI's need for CPU capacity — OpenAI reportedly ported its x86 code base to AWS's Graviton-based ARM CPUs to secure capacity, reflecting how willing developers are to re-engineer when alternative compute is unavailable.8
“As an aside, two large AWS customers have already asked if they could buy *all* of our Graviton instance capacity in 2026 (Graviton is our widely-adopted custom CPU chip)—we can’t agree to these requests given other customers’ needs, but it gives you an idea of the demand.” – Andy Jassy, 2025 Amazon Shareholder Letter7
Enterprise practitioners consistently describe agentic workloads pulling through meaningful spend beyond the core AI services themselves — including databases, GPU-accelerated clusters, Kubernetes, observability, and security tooling — with limited expectation of near-term moderation.9
Industry practitioners also note that growth is not primarily attributable to existing workloads scaling up, but rather to the rapidly expanding volume of new work being done on the cloud, driving exponential increases in compute and network demand.9
GPUaaS Returns In A Supply Constrained Market
The above outlines theoretical IRRs in a balanced market – a market in which neoclouds earn their cost of capital and hyperscalers are able to earn a premium to that “industry floor” and capture economics in ways that are unavailable to neoclouds. While the above model assumes constant pricing across the six-year useful life of a server, in reality, the pricing for GPUs tends to fall over time, with the newest generation GPUs demanding a premium and the later generation GPUs getting discounted. This creates a pricing decay curve, with “realized” pricing over the 6-year useful life (for most GPUs) representing a combination of contiguous rental periods (some 1-month periods, some 3-month periods, some 1-year periods, potentially 3-year periods, etc.).
One would expect to see contracted H100 prices fall between 2023 (first year in service) and 2028 (last year of useful life). However, as discussed in my recent memo on the token demand inflection, compute demand continues to outstrip supply. This is resulting in an inflection in H100 prices across all contract tenors. Below I show 1Y H100 contract pricing estimates based on industry trade press data.
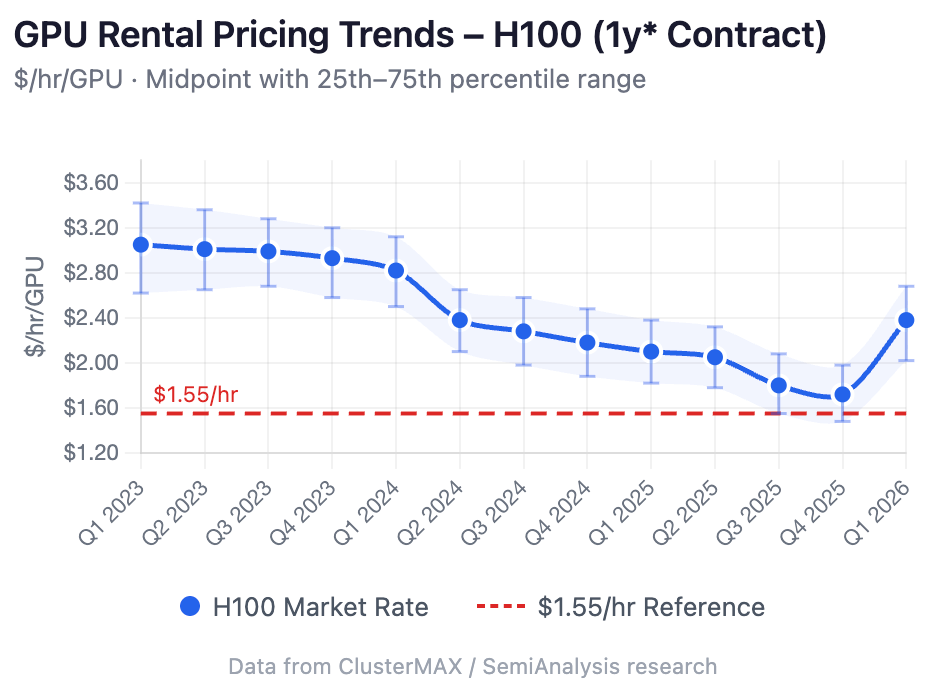
H100 pricing is likely to remain in excess of $1.55 for the foreseeable future. Below I show various EBIT margin, ROIC, and project-level IRR estimates at different realized pricing levels (across the entire six-year useful life). Ultimately, this chart shows (i) just how sensitive project-level IRRs are to realized GPU-hour pricing and (ii) how attractive the project level returns are at $2.00+ H100-hour realized pricing.

My estimates suggest lifetime realized pricing for H100s on rolling 1-year contracts to-date has been in the ~$2.45/hour range (accounting for recent re-bookings through the end of 2026). Under an illustrative scenario where a hyperscaler operates an H100 fleet at that price for four years, the modeled project-level IRR would be in the mid-30s percent range. This is an illustrative sensitivity only, dependent on assumptions around utilization, capital costs, and pricing persistence — actual realized returns will vary materially based on many factors outside of any modeler's control.
A key variable necessary for the hyperscalers being able to earn outsized returns on GPU deployments is for demand to continue to exceed supply.
Demand
Previously I’ve discussed why agentic workflows are materially more token intensive than chat workflows. I believe we are still quite early in the broadening out of agentic workflows from software engineering to general knowledge work. Additionally, I believe the “software engineering” TAM is likely understated, as lower friction with respect to developing programs and applications should result in more software development.
Effectively, there has long been a bifurcation between those who know how to program a computer and those who would like to use a computer to its full extent. The average knowledge worker has always been capability-bound (they don’t know how to get their computer to do what they want it to) rather than compute-bound (insufficient computing resources). As we move towards a world where harnessed intelligence helps knowledge workers direct compute resources more effectively, I believe the line will further blur between what is “software development” and what is simply the new way of doing work.
Additionally, every near/medium term demand signal we have indicates that compute demand continues to massively outstrip supply (hyperscaler commentary, frontier lab commentary, token demand & pricing, expert calls/channel checks, etc.). For the purposes of this analysis, I’d ask the reader to take it as a given that the demand for incremental compute is significant (particularly in a world where agentic workflows are materially more compute intensive than chat workflows).
Supply
On the supply side, consensus is calling for ~20GW worth of global DC additions in 2026, followed by mid-to-high-20s GW additions in 2027/2028 (again, I would reference my “Token Demand Inflection” memo from earlier this year to help translate GW capacity additions into token supply.) However, the sheer size of the data center buildout is beginning to result in delays/timeline slippage.
Sightline Climate has highlighted that only 1/3rd of the US’s planned data center pipeline for 2026 is currently under construction, with 30-50% of the 2026 data center pipeline expected to be delayed.10
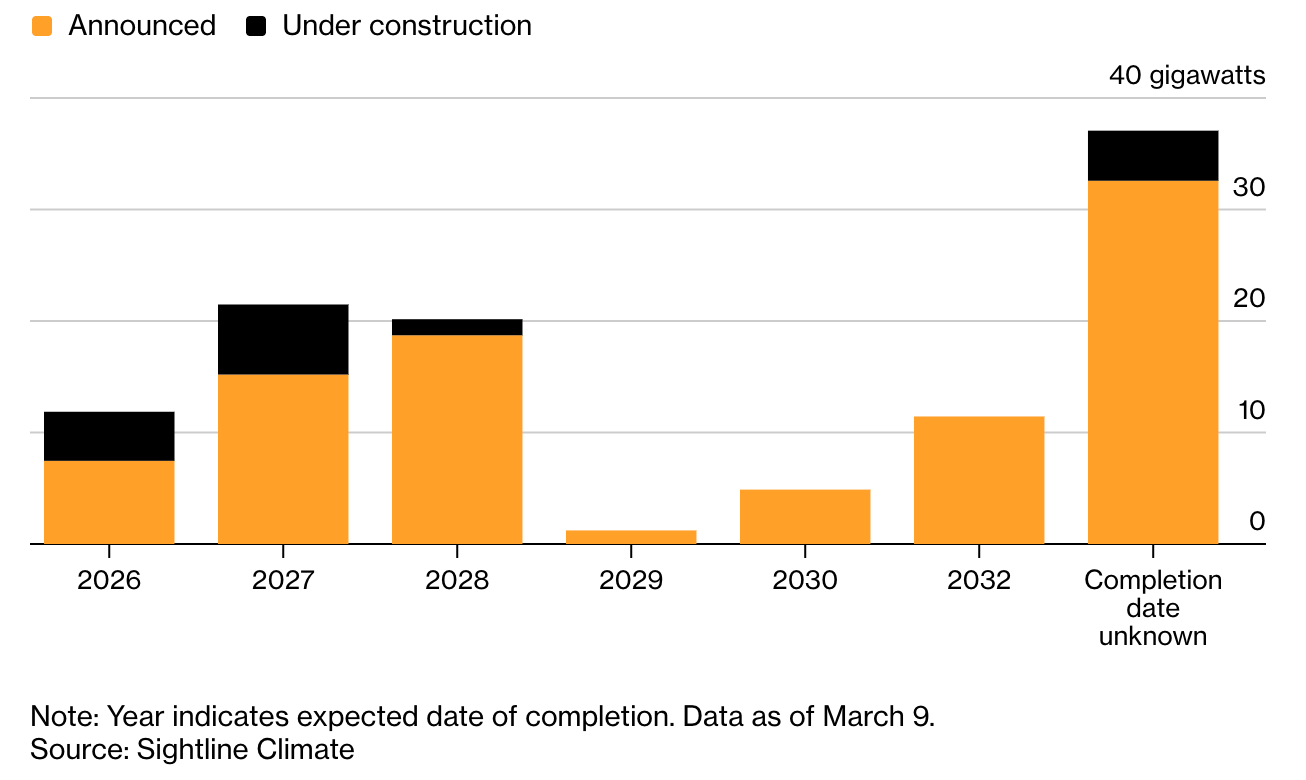
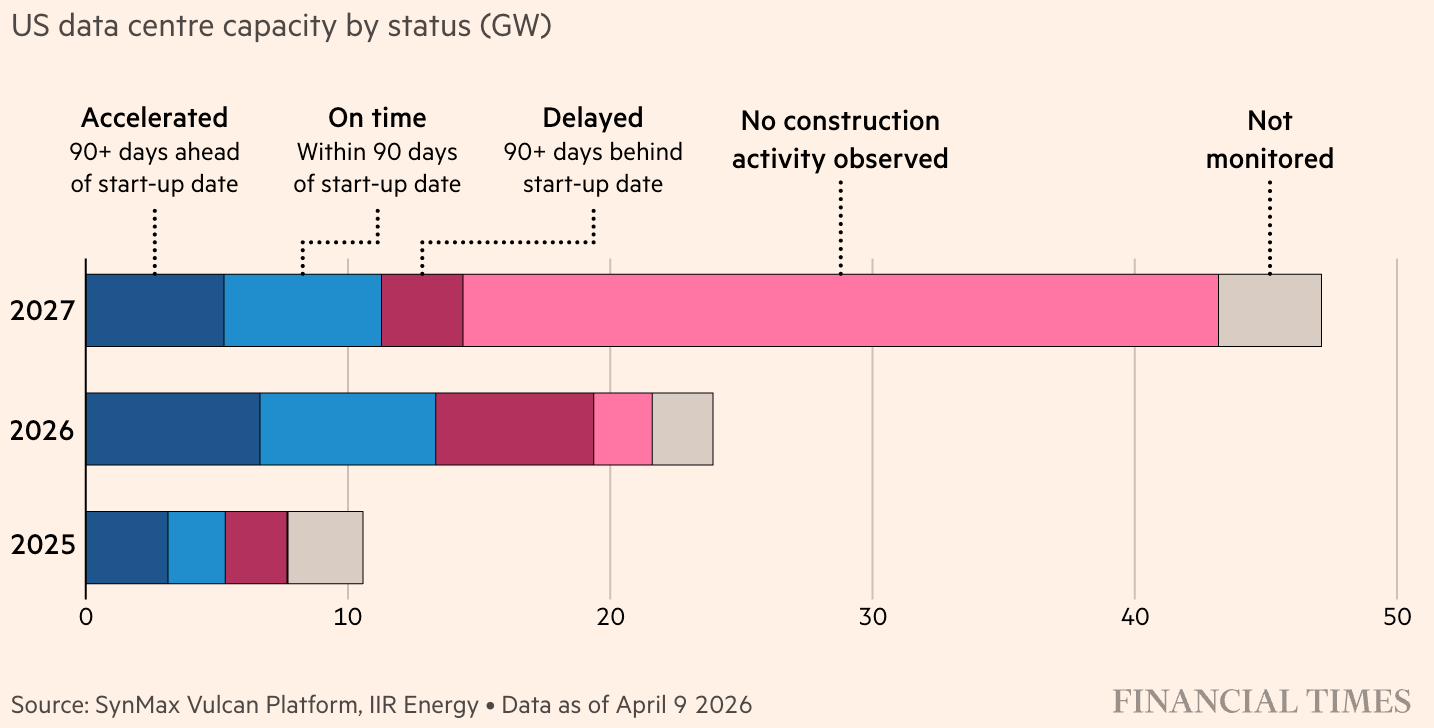
While many attempts to point to “the" bottleneck, there exists a series of co-equal bottlenecks. Effectively, there are a number of critical path items necessary to bringing online DC capacity, and there are supply crunches for numerous critical path items.
NIMBYism
Maine lawmakers recently passed a ban on large data center construction, and at least 10 other states have similar measures under consideration.12
“For 16 years, I have been reporting on land-use fights over energy projects. Over that time, I have interviewed dozens of people from all over the world — including farmers, ranchers, politicians, and ordinary citizens — who are fighting against the encroachment of alt-energy projects. In all, I’ve documented nearly 1,200 rejections or restrictions of solar, wind, and battery projects. But I’ve never seen anything like the raging backlash against data centers.
Since January 1, there have been more rejections or restrictions of data centers in the US than in all of 2025. Furthermore, the number of US data center rejections in 2026 is already nearly equal to the total number of wind projects rejected worldwide in 2025! And more rejections are coming. A recent poll found that 65% of Americans surveyed oppose data centers in their communities.” – AI Rejected: Tracking the Great Data Center Revolt by Robert Bryce13
Industry channel checks indicate that NIMBYism, while not new to construction, has accelerated meaningfully for data center builds in the past year — particularly in areas with wealthier residents. Active litigation against early-stage GW+ sites is now occurring in the Midwest, and developers are spending more on PR-driven community outreach, closed-loop water commitments, and site designs that restrict water use in order to secure local permitting.14
Channel checks also note that community concerns about water usage persist even at sites using closed-loop systems, driving continued investment in community education and stakeholder engagement across both hyperscaler self-builds and colocation providers.14
With 65% of Americans opposing data centers in their communities and active legislation in 10+ states, permitting risk now sits squarely on the critical path for new capacity — particularly for greenfield sites in less urbanized areas (where much of the planned buildout is concentrated).
Power Procurement & Electrical Equipment
The U.S. electrical system was not built for this kind of demand shock. For roughly two decades, load growth was flat, and the entire ecosystem—generation planning, transmission buildout, interconnection processes, regulatory frameworks, and supply chains—optimized around that reality. What we are seeing now is a step-function change driven simultaneously by AI data centers, manufacturing reshoring, and broad electrification. The issue is not just a lack of generation capacity in the abstract. It is that the entire delivery stack—interconnection queues, transmission expansion, substation capacity, and utility planning timelines—cannot scale fast enough to meet large, concentrated loads on acceptable timelines. In many markets, grid capacity is effectively pre-sold years in advance, and the process to bring new capacity online is measured in multi-year increments, not quarters. Behind-the-meter (BTM) generation is often presented as a workaround, but in reality it shifts the constraint rather than removing it. Large-scale BTM requires turbine or engine supply, fuel infrastructure, environmental permitting, and full electrical integration—each with its own bottlenecks and timelines. At hyperscale, BTM projects begin to resemble standalone power plants, with similar capital intensity and regulatory exposure. As a result, most developers are not bypassing the grid so much as layering BTM on top of an already constrained system, using it as a bridge rather than a true substitute.
Even where power can be secured in theory, the physical components required to deliver it are constrained. Lead times for transformers, switchgear, generators, and related high-voltage equipment have extended into multi-year queues. It is becoming increasingly difficult to find fiber optic cable. These are not easily substitutable inputs, and they sit directly on the critical path to energization. The result is that a meaningful portion of announced projects cannot progress from planning to construction, not because capital or demand is lacking, but because the equipment required to translate power into usable capacity is simply not available on the necessary timeline.
Jensen Huang has publicly emphasized that upstream semiconductor capacity (EUV machines, fab capacity, CoWoS packaging) will respond to demand signals on a 2–3 year timeframe, while energy supply and the downstream electrical delivery stack remain the structural long-lead constraint on AI factory buildout.15
Power-and-energy industry specialists describe grid infrastructure as the primary bottleneck for new data center loads, with transmission and interconnection queues constraining additions. Gas turbine lead times have reportedly extended from 2–4 years to as long as 6 years, while standard transformer lead times have extended from 12–18 months up to 36 months for large power transformers. Switchgear demand is accelerating as well, though pricing pressure remains most acute on transformers, which have become the pacing item for most grid infrastructure projects.3
Industry experts working in power markets emphasize that grid-connected generation additions take 5–6 years across major ISOs (ERCOT, MISO, SPP, Southeast), while hyperscale load additions are expected within 2–3 years — creating a persistent imbalance as residual grid capacity is absorbed. Beyond 2028, industry sources expect most new loads will rely on bring-your-own-generation/capacity (BYOG/BYOC) arrangements. The CapEx trade-off is meaningful: grid connection costs roughly $100K–$500K per MW versus $1.5M–$2.5M per MW for on-site gas turbines and $4M–$5M per MW for fuel cells, which keeps grid-connected projects attractive even in suboptimal locations.9
Trade-show commentary suggests on-site power generation equipment demand remains robust, with grid-interconnection backlogs running ~5–7 years. Gas turbines and large engines are the most common bridge-power solutions. Gas turbine lead times are reportedly ~3–5 years, with major OEM order books largely closed into 2030. Large-engine lead times are closer to 2–3 years.16
Data center operators report 52+ week lead times for high-strand fiber and armored fiber bundles, forcing a shift from just-in-time procurement to longer-term stocking programs. Available supply is reportedly clearing within 24–48 hours when it becomes available, with industry sources attributing a portion of the tightness to hyperscaler pre-buying.14
Additional operator feedback notes individual AI data center sites consuming tens of millions of fiber strands, with supply buildout unlikely to keep pace with AI-driven demand over the medium term.14
Industry sources familiar with hyperscaler power strategy describe a significant timeline spread for on-site "power foundry" projects. Where the customer partners with a vertically integrated energy company — one that already owns gas extraction, transmission, and supply infrastructure — getting 500 MW to 1 GW online may be achievable within 12–18 months. For non-integrated buildouts, or those requiring multi-source integration (solar, wind, gas, and storage), timelines typically run 24–36 months or longer. Separately, lead times for critical electrical equipment (generators, turbines, switchgear) are reportedly in the 100–150 week range, with normalization not expected until 2029 at the earliest.9
“Almost half of the US data centers planned for this year are expected to be delayed or canceled. One big reason is the shortage of electrical equipment, such as transformers, switchgear and batteries. They are needed not just for powering AI, but also for building out the grid that is seeing increased consumption from electric cars and heat pumps. US manufacturing capacity for these devices cannot keep up with demand, and the scarcity has caused data center builders to rely on imports.” – Bloomberg News (04-01-2026)17
In sum, the power and electrical equipment constraints facing the data center buildout are not temporary supply chain disruptions — they reflect deep structural mismatches across the entire stack. Grid interconnection timelines of 5-6 years fundamentally lag the necessary timelines, and behind-the-meter generation shifts rather than removes the constraint. Transformer lead times have extended to 36 months, gas turbine order books are closed through ~2030, and switchgear demand is surging with no near-term supply response. Even ancillary inputs like high-strand fiber are now facing 52+ week lead times as hyperscalers pre-buy available supply. Taken together, these co-existent bottlenecks are unlikely to meaningfully ease before 2028-2029.
Skilled Labor
Even after power is secured and equipment is available, the final constraint is the specialized labor required to actually build and energize these systems. While generic benchmarks often suggest less than one worker per MW, real-world gigawatt-scale projects imply meaningfully higher labor intensity. Meta’s El Paso campus suggests roughly 4 workers per MW at peak, its Richland Parish site closer to 2.5, and OpenAI/Oracle’s Abilene project around 1.3, implying a practical range of roughly 1 to 4 workers per MW depending on design, phasing, and level of modularization. Applied to a 20 GW annual buildout, this translates to roughly 25,000 to 80,000 concurrent construction workers, with a reasonable midpoint closer to 40,000–60,000. That level of demand is not constrained by the total U.S. construction workforce, but by a much narrower set of roles – mission-critical electricians, high-voltage and substation crews, controls and commissioning technicians, and experienced MEP project managers – which are already in limited supply and heavily shared across grid expansion and industrial megaprojects. As a result, labor should be viewed as a soft cap on build velocity: not a hard national limit, but a factor that increasingly manifests as longer timelines, rising subcontractor costs, and execution risk as annual build rates move into the high-teens (GWs) and beyond.
Industry commentary points to accelerating labor rates and construction cost inflation, driven by shortages in construction, electrical work, and plumbing — pressures exacerbated as data center buildouts increasingly concentrate in low-population areas.16
Jensen Huang has also publicly described labor — plumbers and electricians specifically — as the hardest bottleneck to solve, noting that the industry is a healthy one where demand exceeds supply across the skilled trades.15
Summary
I believe these co-existent bottlenecks significantly increase the likelihood that the US data center buildout fails to keep up with demand in the near-to-medium term. This will lay the groundwork for a favorable pricing environment for GPU-cloud providers, allowing them to earn outsized IRRs if demand continues to outpace supply.
Takeaways From Bottom-Up Analysis
Ultimately, baseline industry returns on capital will be established by the neoclouds’ cost of capital. Hyperscalers are in an advantaged position versus neoclouds due to their lower cost of capital, bargaining power vs. merchant silicon providers, ability to charge higher GPU rental prices, custom AI accelerators, revenue share with frontier labs, and embeddedness in traditional compute environments necessary to enable agentic workflows. Additionally, a supply constrained state results in pricing power (and subsequent high returns on capital) for the businesses able to bring capacity online.
Competitive Positioning
There are three relative parties worth considering hyperscaler competitive positioning vis-à-vis.
- Silicon Providers (As Suppliers)
- Frontier Labs (As Customers)
- Frontier Labs And Neoclouds (As Competitors)
Below I comment on the hyperscalers’ competitive positioning vs. each of these parties, and ultimately highlight a number of key points worth considering when evaluating the hyperscalers’ likelihood of establishing/defending their competitive positioning in “GPU-cloud.”
Silicon Providers
In CPU-cloud, the primary chip suppliers are Intel/AMD. Amazon has spent years developing custom silicon (Nitro, Graviton, etc.) to reduce its reliance on out-of-the box merchant silicon — gaining bargaining power. Additionally, the CPU-cloud ecosystem has been in a relatively stable supply/demand balance.
With the GPU-cloud business, Nvidia has more bargaining power than Intel/AMD due to the overwhelming demand for Nvidia chips and the relatively less mature state of custom silicon alternatives.
However, one potential counter to this is that while customers often choose what type of hardware a CPU workload runs on (Intel virtual machine, AMD instance, Graviton instance), which has slowed the adoption of Graviton as many workloads/tools continue to require x86 environments, higher-level AI services such as Bedrock can be served over AWS silicon. In CPU-cloud, the customer chooses the hardware, whereas outside of dedicated capacity blocks, AWS can choose to run AI inference provisioned via Bedrock and other AI/ML PaaS on Trainium.
Over time, the success of non-Nvidia AI accelerators will help to determine the relative bargaining power of the hyperscalers. This relates to both their own first-party chip efforts (TPU, Trainium, Maia) and alternative merchant silicon players (AMD, the OpenAI/Broadcom ASIC, Cerebras, etc.).
Frontier Labs (As Customers)
While the frontier labs have significant bargaining power due to the size of the demand that they bring to the hyperscalers, the hyperscalers control a scarce resource from the perspective of the labs – compute capacity. Both Anthropic and OpenAI have indicated that their revenues are primarily limited by compute capacity, and considering hyperscalers are able to secure tremendous amounts of compute capacity for the frontier labs, hyperscalers are able to earn strong returns via attractive pricing, forcing custom silicon, and negotiating attractive revenue share agreements for tokens sold over hyperscaler LLM gateways.
However, OpenAI and Anthropic have significantly more bargaining power than traditional enterprises in a CPU-cloud world. At this point in time, the majority of “AI ARR” is being driven by these two companies. The hyperscalers receive lower returns on capital on investments made on behalf of these large frontier labs (as evidenced by lower GPU/hr pricing) than they do on other enterprise workloads. However, bottlenecks and supply constraints shift bargaining power back to the hyperscalers. In a world where power, labor, and compute are scarce resources — the hyperscalers ability to bring online capacity (effectively solving these bottlenecks better than neoclouds or the AI labs could do so themselves) should earn an attractive return on capital for doing so. Amazon has a significant amount of power capacity locked up through long-term PPAs, and the chip shortage has almost certainly been a boon to Amazon’s custom silicon program to date (as compute capacity “beggars” can’t be choosers).
There has been speculation that at some point could the frontier labs decide to in-source their compute? First, OpenAI’s original intentions with the Oracle/Softbank partnership around Project Stargate was to do exactly this – build their own first party capacity. However, reporting indicates that as the project moved from the announcement to implementation phase, Softbank and Oracle strongly pushed back on the idea that they would be putting up the capital for OpenAI to “own” the capacity. Additionally, both OpenAI and Anthropic are expected to be cashflow negative until 2029-2031. Renting 1MW of GPU capacity costs $11-$12M, but buying 1MW requires approximately $35M of CapEx. For businesses in a hyper-intense competitive environment deep in the trough of the cashflow J-curve, it seems hard to argue that the best use of capital at this point in time is to accelerate internal capacity builds. If OpenAI and Anthropic attempt to build out their own compute capacity in 2030+, my best guess is that this would go to serve incremental compute capacity needs (vs. replacing current hyperscaler provided capacity).
Frontier Labs (As Competitors)
The frontier labs represent a potential long-term competitive threat to the hyperscale platform layer. OpenAI, Anthropic, and other frontier labs each have incentives to build direct enterprise relationships — capturing more of the value chain by offering their own managed inference, fine-tuning, and orchestration services (as OpenAI has begun doing with its API platform, and Anthropic with direct API sales).
However, there are meaningful structural constraints on how aggressively the frontier labs may pursue this strategy. Game theory should limit defection. If Anthropic were to meaningfully pull back from Bedrock/Vertex in favor of its own direct platform, it would create an opening for OpenAI, Gemini, Mistral, and others to deepen their hyperscaler integrations and capture the enterprise share Anthropic vacated. With roughly five credible frontier labs and a growing set of notable secondary players (Chinese labs, open-source ecosystems), no single lab has the market power to force enterprises off the hyperscaler platforms without risking significant share loss. The hyperscalers' model-agnostic positioning (Bedrock, Vertex, Foundry) is specifically designed to exploit this dynamic — any lab that withdraws simply makes the remaining options more prominent.
Enterprise procurement inertia favors hyperscalers. As documented in the moat section below, enterprises strongly prefer to consume AI through existing cloud commitments (EDP burn-down), established security/governance frameworks, and familiar tooling. A frontier lab attempting to sell directly to the enterprise must replicate not just the inference API, but the full stack of VPC integration, IAM, compliance certifications, SLAs, cross-region redundancy, and SI ecosystem support. This is a multi-year, capital-intensive undertaking that is not necessarily a part of the labs' core competency.
Additionally, the labs need the hyperscalers as much as the hyperscalers need the labs. Frontier labs remain compute-constrained and capital-hungry. Their dependency on hyperscaler infrastructure (and capital) for training runs gives the hyperscalers significant leverage to negotiate favorable terms, including revenue shares and custom silicon commitments. Anthropic's multi-billion dollar commitments with Amazon and Google, and OpenAI's deep integration with Microsoft, create structural dependencies that would be costly and time-consuming to unwind.
Net, while frontier labs will likely continue expanding their direct API businesses, a full-scale assault on the hyperscaler platform layer would be strategically irrational for any individual lab given the current competitive landscape. The more likely equilibrium is a coexistence model where labs maintain direct API channels for some use cases while hyperscalers dominate enterprise production deployments. Frankly, the conversation regarding the frontier labs reducing the hyperscalers to “dumb pipes” reminds me of the 2021/2022 era conversations around hyperscalers vs. “best-in-breed” PAAS/SAAS providers who were going to “dominate the platform layer” and leave AWS as simply providing “commodity compute.”
Additionally, recent industry reporting provides useful context on enterprise demand dynamics in the frontier-lab vs. hyperscaler relationship.
Recent reporting (The Verge, April 2026) cited internal OpenAI commentary suggesting that while the Microsoft partnership has been foundational, it has limited OpenAI's ability to reach enterprises already standardized on AWS Bedrock — and that inbound demand following the Amazon partnership announcement in late February has been notably strong.18
My takeaway from the above is not that Amazon is winning vs. Microsoft, but rather it illustrates that for most organizations their primary cloud service provider is “where they are,” and that the frontier labs need to “meet them there.”
Neoclouds (As Competitors)
The “neoclouds” such as CoreWeave, Lambda, Nebius, and Crusoe are likely more threatening than the colocation providers in the CPU world (Digital Realty, Equinix, etc.) due to the supply/demand imbalance and Nvidia’s perceived self-preferencing of the neoclouds. While neoclouds don’t receive quite the level of discounts that the hyperscalers receive, they do get similar allocation priorities. Overall, the neoclouds tend to be much more aggressive on price in an attempt to gain market share.
There is some mitigation here due to the fact that industry commentary indicates that neoclouds have immature higher-level services capabilities (“bells and whistles”) and the majority of their revenue is comprised of the AI Labs themselves and third-party deals struck with the hyperscalers (who they have low bargaining power over) vs. enterprise production use cases.
Key Points For Hyperscaler Moats
Data Security, Governance, and Regulatory Compliance: For enterprises (especially in regulated sectors like healthcare or finance) security and compliance are paramount. Hyperscalers already have pre-approved Virtual Private Clouds (VPCs), strict Identity and Access Management (IAM) controls, and robust governance frameworks. Routing AI queries through native hyperscaler platforms keeps sensitive data within an existing, secure boundary rather than sending it over the public internet to a third party.
Regulated-industry practitioners consistently prefer hyperscaler platforms because the tooling is pre-built, materially simplifying compliance for highly-regulated workloads.9
Practitioners I've spoken with consistently note that consuming AI models through hyperscaler gateways (Bedrock, Azure OpenAI) is meaningfully more secure than calling the frontier lab APIs directly — hyperscaler guardrails keep data within the customer's VPC rather than traversing the public internet.9
On data gravity, governance, and IAM, operators in the space report that hyperscaler-plus-LLM offerings consistently outperform direct frontier-lab APIs for enterprise customers.9
Data Gravity, Egress, and Ecosystem Integration: Enterprise data already resides in hyperscaler environments (like AWS S3 buckets or Azure Blob storage). It is vastly more efficient to bring the AI model to where the data naturally sits. Calling models directly through external frontier labs or neoclouds introduces massive egress fees for moving the data out of the hyperscaler's ecosystem and adds significant network latency.
Enterprise architects describe data gravity as the fundamental driver of hyperscaler lock-in: the bulk of enterprise data already sits in services like S3, which heavily biases AI workloads toward the incumbent provider.3
Practitioners emphasize two frictions in using out-of-ecosystem models: egress fees for moving data outside the hyperscaler, and added network latency.9
While frontier labs have begun offering managed services where customers can bring their data, people closer to these deployments note that relocating enterprise data from an existing hyperscaler environment is operationally difficult in practice.9
Procurement Simplicity and Existing Financial Commitments (“One-Stop Shop”): Large enterprises typically have very large, pre-existing, multi-year consumption commitments with hyperscalers. It is much easier for procurement teams to fund AI initiatives by burning down existing, pre-committed cloud credits than it is to vet, approve, and sign a net-new contract with a frontier lab or neocloud.
System integrators report that enterprise commitment structures increasingly blend AI services (Vertex, Azure OpenAI, token-based pricing) into core cloud commits — typically 10–30% of the budget — which procurement teams view as high-value given the ability to consume AI out of an already-approved pool of assets.9
Sources inside these enterprises describe reluctance to adopt new services outside their primary cloud provider — driven by commitment structures, governance standardization, and a strong preference to avoid multi-cloud operational complexity.9
Enterprise practitioners confirm that it is far easier to consume AI via existing hyperscaler credit burn-down than to secure incremental budget for a net-new vendor — a procurement dynamic that meaningfully advantages the incumbent cloud provider.9
Model Agnosticism and Multimodal Orchestration: Enterprises want to avoid vendor lock-in with any single AI model. Hyperscaler managed services act as an orchestration layer that provides a unified API, allowing developers to seamlessly test, evaluate, and swap out different models (Anthropic, Meta, Mistral, OpenAI) on the back end without having to re-architect their applications.
Industry research has noted Bedrock's origin story: pivoting from the in-house Titan model to a marketplace-design (one API fronting Anthropic, Cohere, AI21, and others) enabling enterprise customers to swap underlying models without re-architecting their applications.16
Several insiders frame Bedrock as an "anti-lock-in" play — offering enterprises multi-model optionality where consuming models directly from a single frontier lab (or a tightly integrated alternative like Gemini via GCP) would imply vendor concentration.9
Practitioners note that the gateway architectures (Bedrock, Foundry) make it materially easier to be model-agnostic and swap underlying LLMs on the back end without application-layer rework.9
Enterprise Trust, SLAs, and Operational Resilience: Mission-critical enterprise applications require extreme reliability. Hyperscalers possess massively scaled, globally distributed infrastructure that allows them to offer ironclad Service Level Agreements (SLAs) for uptime and cross-region disaster recovery, guaranteeing that highly-available enterprise workflows will not go offline.
Enterprise CIOs running pilots with hyperscaler alternatives describe meaningful gaps in SLA coverage, global footprint, and cross-region redundancy relative to the hyperscalers, creating resilience concerns for mission-critical workloads.9
Industry research has documented deep switching-cost moats at hyperscalers: multi-year EDP commitments, governance standardization (most enterprises cannot practically run multi-cloud for compliance reasons), and CISO perceptions that hyperscaler security and reliability significantly exceed what enterprises can achieve in-house.16
Industry practitioners consistently describe significant stickiness at existing hyperscalers: enterprise data already lives in AWS, Azure, or GCP, and new applications are built to leverage that data in place.9
Enterprise practitioners describe paying a premium to access frontier models via hyperscaler gateways (e.g., Azure OpenAI) in exchange for SLAs, maintenance, and first-class integration with the rest of the cloud environment.9
System integrators report growing agentic AI experimentation across platforms like SAP Joule and Google Vertex, though with audit and accuracy caveats around financial-transaction use cases. Most client agent development is occurring on hyperscalers using third-party frontier models.16
System Integrator (SI) Ecosystem and Support: Hyperscalers have deeply entrenched relationships, co-investment funds, and training programs with the world's largest IT consulting firms and System Integrators (SIs). When an enterprise hires external technical talent to deploy an AI solution, those consultants naturally rely on the hyperscaler tools they are already certified to use and comfortable building with.
System integrators describe a strong preference to build on hyperscaler-native building blocks as the tooling is familiar, the vendor is already approved, and the hyperscalers work closely with the major consulting firms on go-to-market.9
Consultancy practitioners describe formalized joint go-to-market programs with hyperscalers: co-branded marketplace offerings, hyperscaler-funded POCs, dedicated partner teams, early access to features and roadmaps, and co-investment in industry solutions.9
System integrators are reporting a meaningful inflection in SaaS-displacement deals in 2026, spanning CRM, ServiceNow, SAP, and security software — driven by customer frustration with software price increases and enthusiasm for building AI-native replacements. Hyperscalers are reportedly funding these deals directly via "SaaSification" programs at several million dollars per use case.16
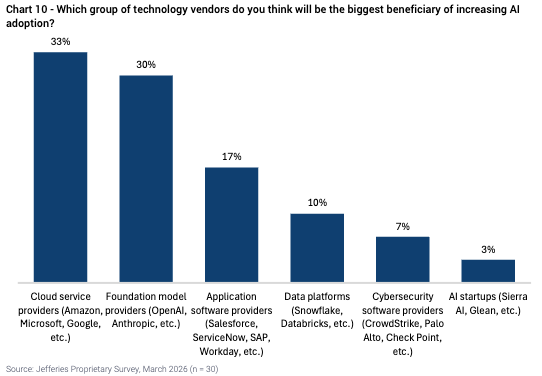
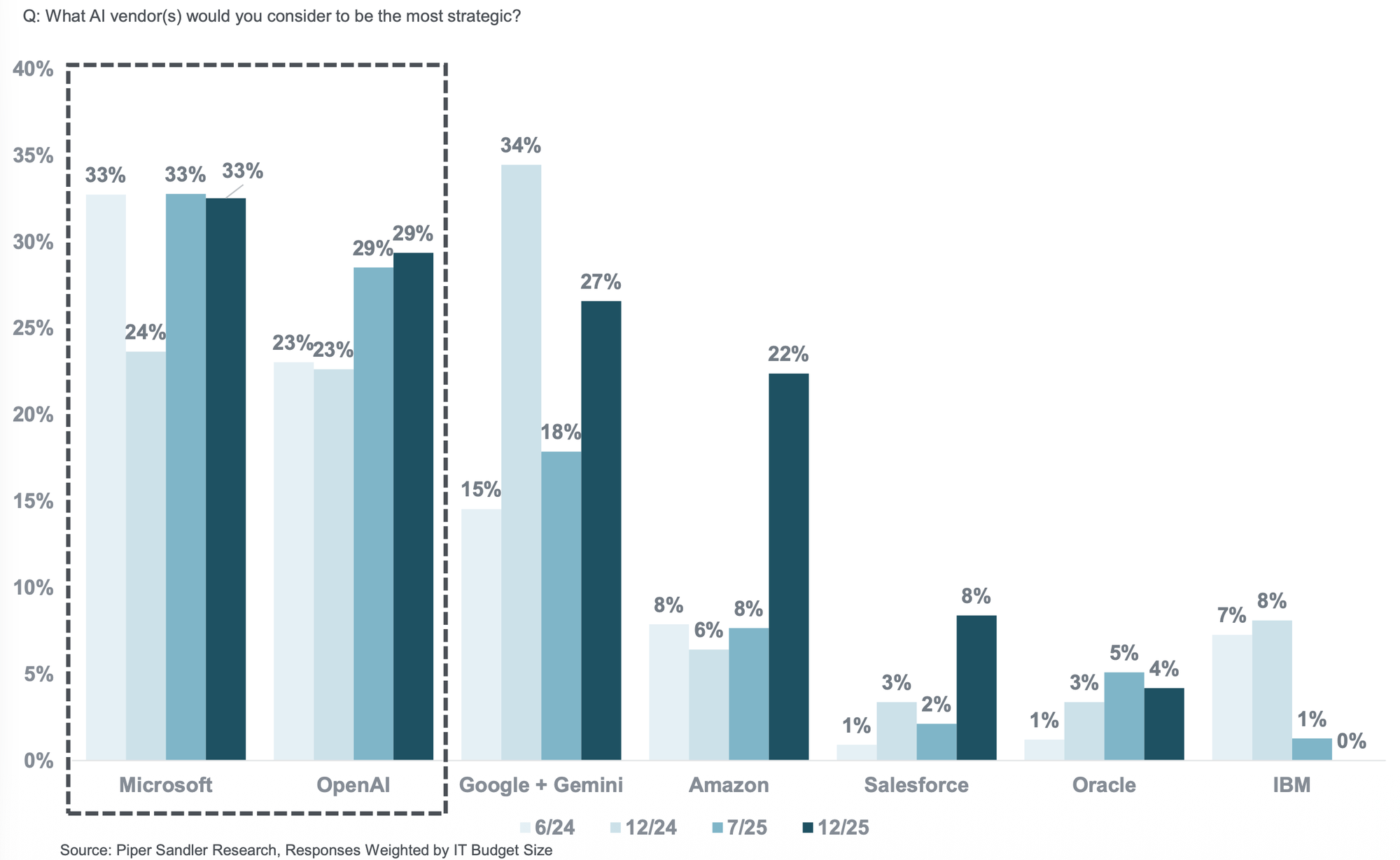
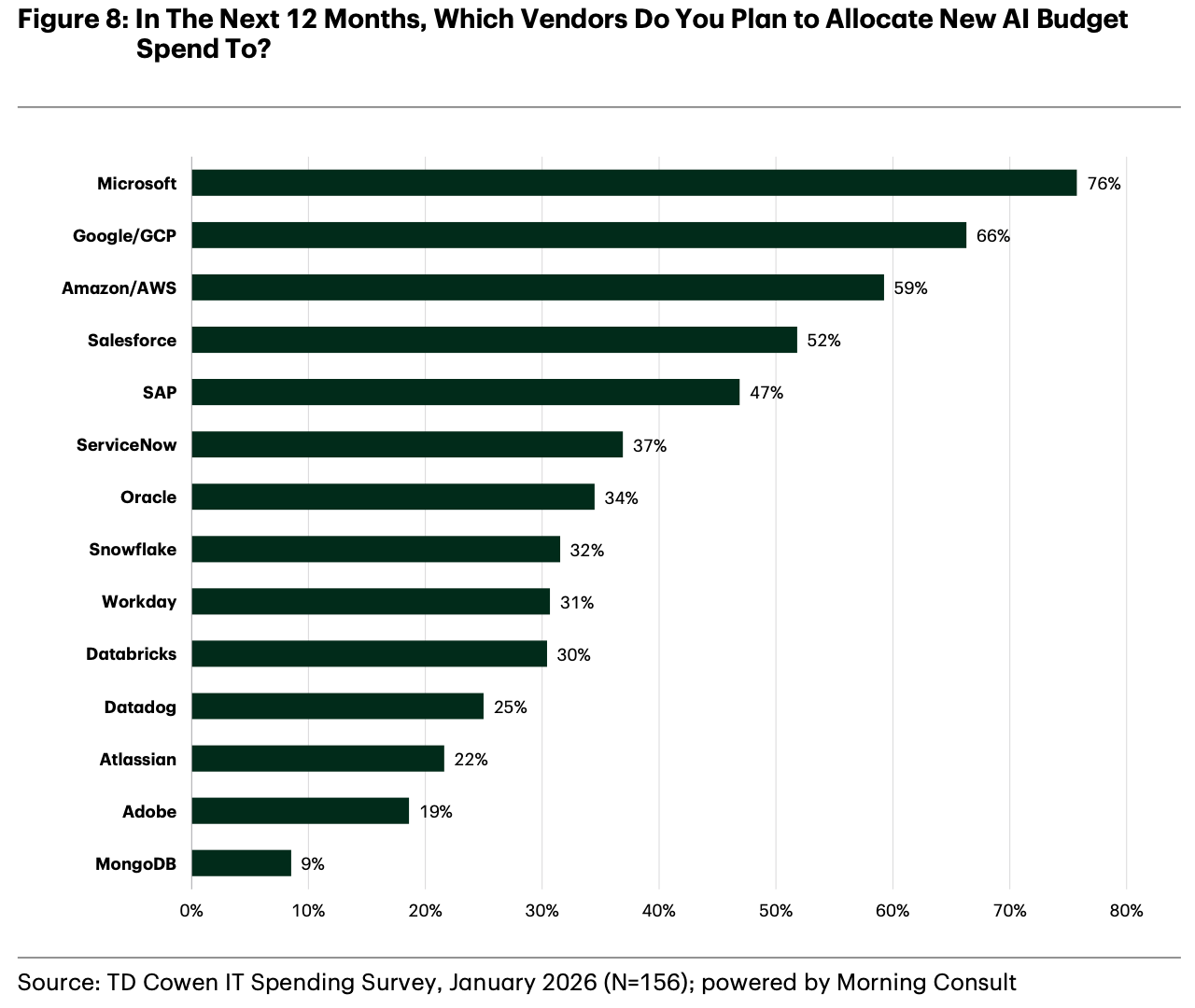
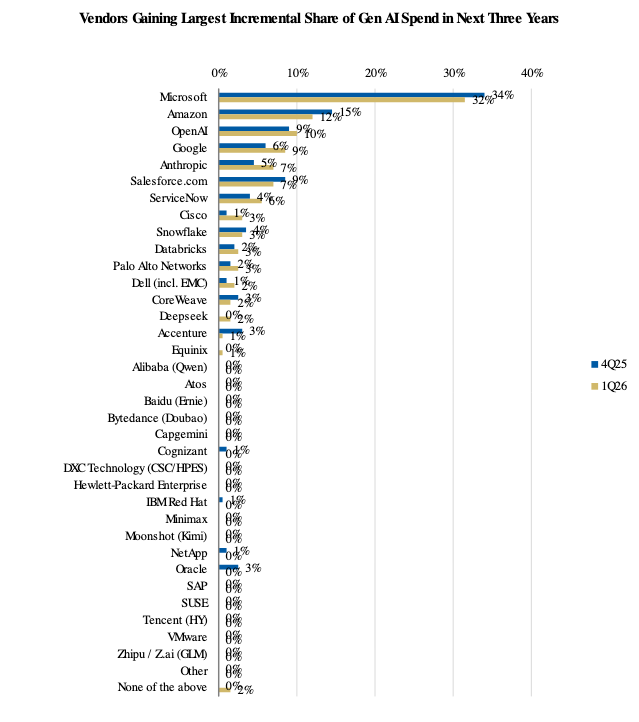
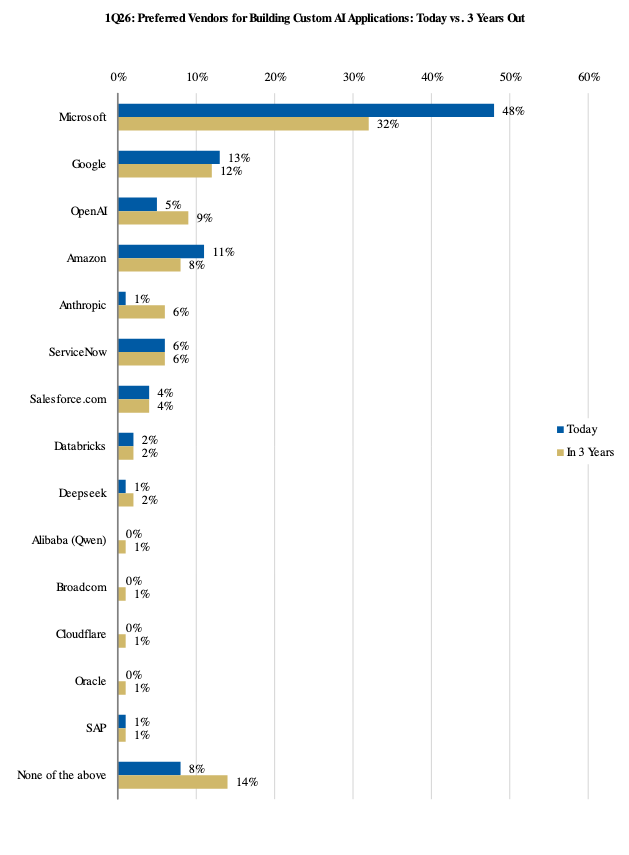
CIO Surveys
To reinforce the above points, I am also highlighting a number of industry CIO surveys illustrating how organizations are leaning heavily on their cloud service providers to help with AI adoption.
Top-Down Analysis
AWS ROIC Estimates
We can make inferences from Amazon’s financial statements and recent management commentary in an attempt to estimate the early returns on capital for AWS’s GPU-cloud build out (this is easiest for AWS because Amazon explicitly calls out AWS related capital expenditures in its filings).
In the below exhibit I’m assuming the following to arrive at an estimate of Amazon’s ROIC (to-date) on this build out (Note: Q1 2024 was the first quarter Amazon’s capital intensity began to increase vs. prior norms).
- AWS’s revenue growth rate would’ve been ~15% in each quarter excluding the tailwind from AI Services. Andy Jassy also recently mentioned that AWS’s run-rate AI revenue surpassed $15B in Q1 2026
- AWS’s capital intensity would’ve remained in the 28-30% range if not for the additional investment in AI CapEx
- Amazon has gradually shifted the percent of CapEx dedicated towards long-lived assets (the data center kit excluding servers) from 60% to 40% (in-line with Microsoft commentary) over the past 8 quarters
- All short-lived assets (6Y useful life) are revenue generating on a two-quarter lag
- All long-lived assets take (20Y useful life) are revenue generating on a five-quarter lag
- Depreciation reduces the asset base, which is the correct assumption as NOPAT (the denominator in ROIC) is derived from EBIT, a post-depreciation number
- I use the average “revenue generating” invested capital from the current quarter and the prior quarter and compare it to the “run-rate” AI revenue (quarterly AI revenue * 4 quarters)
- I assume a 30% EBIT margin for AI revenues, which I think is reasonable considering AWS produced greater than ~30% incremental EBIT margins through this period
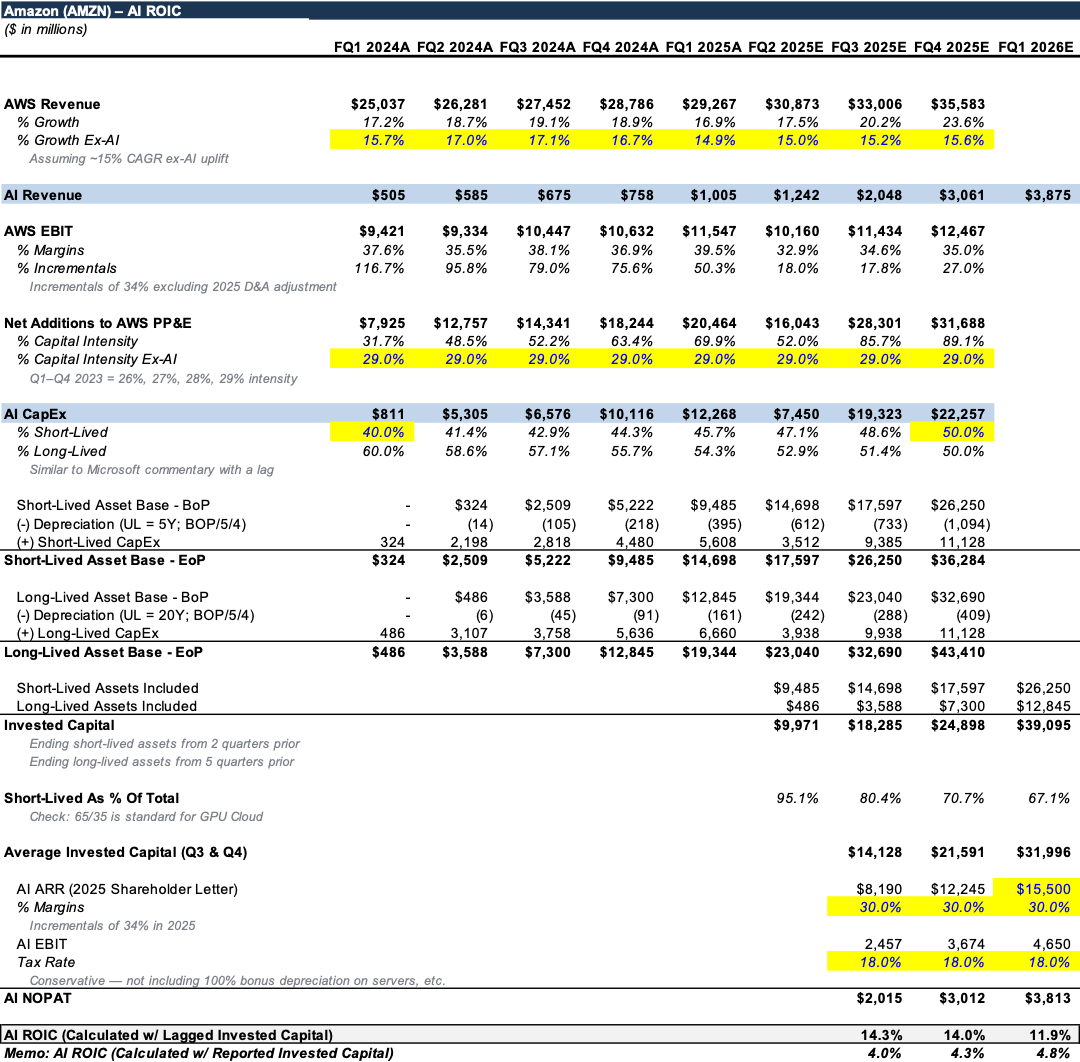
The upshot is that as of Q1 2026, I believe Amazon has ~$32B of revenue generating invested capital supporting ~$15.5B of AI revenue, ~$4.7B of AI EBIT (30% margins), and $3.8B of NOPAT (18% tax-rate, no credit for bonus depreciation).
This produces a ~12% ROIC, which I believe is a healthy return for a rapidly scaling business still in its early innings – and importantly, this figure is likely much closer to an optical trough, rather than a reflection of the steady state. Importantly, even at this early-stage ROIC, AWS is generating positive EVA – as ~12% roughly approximates the cost of capital for a neocloud like CoreWeave, while Amazon's own cost of capital is meaningfully lower (likely in the high-single digits), implying a non-zero spread.
Amazon addressed this dynamic in its 2025 shareholder letter, explicitly noting that AWS must deploy capital 6-24 months ahead of revenue recognition across data centers, chips, and networking. Management emphasized that periods of rapid growth temporarily depress near-term free cash flow and reported returns as CapEx outpaces revenue, but that these assets generate highly attractive returns once capacity is monetized. Amazon framed the current AI buildout as a repeat of prior AWS investment cycles – with early cash flow pressure followed by substantial downstream revenue, ROIC, and FCF expansion.7
Additionally, for a long-term (multi-year) fixed-price capacity commitment, year one of the contract is optically the worst from a reported ROIC perspective: the full capital base has been deployed, but depreciation has not yet reduced the invested capital denominator. As the asset depreciates over its useful life while contracted revenue remains fixed, reported ROIC mechanistically improves – even with no change in pricing or utilization. In other words, the ~12% ROIC I estimate for Q1 2026 reflects a snapshot at the point nearing maximum capital intensity relative to revenue, and the lifetime project-level IRR on this invested capital is likely meaningfully higher than the early reported ROICs would suggest.
Key Takeaways
Ultimately, I believe the hyperscalers' AI CapEx programs are likely to earn attractive returns on invested capital. Key conclusions include:
- Neocloud breakeven economics (~$1.55/hr, ~12% unlevered IRR) establish the industry's base return on capital. Hyperscaler structural advantages (procurement discounts, pricing power, custom silicon, and revenue share agreements, etc.) push project-level returns into the high-teens or better.
- Supply-side bottlenecks across power, electrical equipment, labor, and permitting are unlikely to meaningfully ease before 2028-2029 at the earliest. This sustains pricing power well above balanced-market levels, with realized H100 pricing to-date (~$2.45/hr) implying >30% project-level IRRs.
- Top-down, AWS's AI-specific invested capital is generating ~12% ROICs at what is likely approaching an optical trough – with CapEx deployed 6-24 months ahead of revenue recognition. Lifetime project-level IRRs should be meaningfully higher, and reported ROIC should also improve on a project-by-project basis as the capital base depreciates against contracted revenue.
- Custom silicon programs (TPUs, Trainium, Maia) are an underappreciated source of ROIC upside — both through lower internal compute costs and through capital-light licensing deals (e.g., the Google/Anthropic/Broadcom TPU arrangement).
- Revenue share agreements with frontier labs provide high-margin, capital-efficient revenue that partially offsets the lower GPU-hour pricing extended to large AI lab customers. These revenue shares should grow as enterprise AI adoption accelerates and the mix shifts from training to inference.
- The shift from chat to agentic workflows is not only advantageous to the hyperscalers due to the general increase in compute demand, but also is advantageous due to the fact that agentic workflows touch more resources in the traditional compute environment (where hyperscalers are deeply entrenched).
- Hyperscaler competitive positioning reinforces attractive returns. Data gravity, security/governance requirements, EDP burn-down dynamics, model agnosticism, and SI ecosystem entrenchment create layered switching costs that should insulate the hyperscalers from neocloud price competition and frontier lab disintermediation.
Developments To Monitor
Below I am highlighting areas to continue monitoring concerning hyperscaler returns on capital / competitive positioning.
- A discontinuous breakthrough in model efficiency that materially reduces GPU-hours needed per unit of economic output (even as total demand grows). This would likely result in a temporary overbuild, leading to compute demand outpacing supply, leading to poor medium-term returns for the hyperscalers. A counter-argument to this is that hyperscalers would still be able to sell the traditional compute and AI-services that are “attached” to GPU-cloud, and likely in a much more capital efficient manner long-term.
- Continued concentration of AI ARR among only one or two frontier lab customers poses a risk. The economics of the hyperscalers will look different depending on whether or not xAI, Meta Superintelligence Labs, Microsoft’s frontier model efforts (with the benefit of OpenAI’s IP), and other open-source competitors can stay near enough to the frontier. A hypothetical scenario that would be negative for the hyperscalers is a world in which Anthropic is able to build a genuine point of differentiation (proprietary automated AI researchers, deep integration between model and “harness” layers, etc.) to a degree that Anthropic can effectively dictate that enterprises re-architect their IT stack around Anthropic. The best counter-argument to this is that over the past ~9 months, ChatGPT, Claude, Gemini have all been perceived to be the “most advanced” model – and that there will continue to be leap-frogging.
- Enterprise demand for AI failing to accelerate further. While we are currently seeing an explosion in token demand, it’s possible to argue that token demand is growing due to some combination of (i) everyone wanting to be “front-footed” with respect to AI and (ii) the frontier-labs currently under-pricing tokens to drive adoption – but that both of these factors artificially inflate demand vs. actual productivity gains or ROI-based measures. Additionally, the majority of the demand has come from software engineer/coding customers, and coding just so happens to be a “highly definable” process that is easy for an LLM to tackle, whereas the majority of knowledge work is more loosely defined and is therefore less “automatable.” If “token demand” fails to broaden out from the use cases of coding and producing “AI-work slop”, enterprises may pull back on AI spending as costs are growing rapidly but productivity gains fail to materialize.
Additional Thoughts
- Below are some thoughts I’m not attempting to fully substantiate, but that have been percolating as I’ve been working through researching/writing.
- While the current consensus seems to be “long Anthropic, short OpenAI,” and while I deeply applaud Anthropic’s recent product velocity as both a user of the products and a business analyst, if the frontier labs are truly compute constrained, OpenAI appears to be on better footing over the next few years. After OpenAI’s September 2025 blitz to secure ever-increasingly ridiculous-sounding amounts of capacity, Dario went on the interview/podcast circuit highlighting Anthropic’s desire to expand its compute commitments “prudently.” The implication was that OpenAI was being imprudent/reckless. Now however, Anthropic’s capacity crunch is leading to aggressive rate-limiting, decreased product up-time/reliability, and allegedly, an inability to serve its most advanced models. Codex has quickly caught up to Claude Cowork from a capability perspective, and at this point, many users report less aggressive rate-limiting and more consistent up-time. If product differentiation/model leadership proves temporal, then secured compute capacity becomes a medium-term advantage for OpenAI.
- We are likely at the beginning stages of a CPU shortage considering just how CPU intensive agentic workflows are and how early we are in agentic diffusion. AMD, Intel, and Amazon (via Graviton) are all effectively sold-out of CPU capacity, and this dynamic should only worsen in the coming quarters. AMD has a number of potential tailwinds worth observing: a share-gaining CPU franchise in a tightening supply environment, its #2 merchant silicon position, publicly reported equity investments from OpenAI and Meta, multi-customer inference workloads (OpenAI, Meta, Oracle, Microsoft, and Anthropic have each disclosed or been reported to run certain workloads on AMD chips), and a growing share of TSMC's advanced packaging allocation. Whether AMD ultimately captures these opportunities will depend on software-stack maturity and customer adoption. This paragraph is observational and not intended as a recommendation regarding AMD securities.
- Above I’ve given a defense of the hyperscale business model at large, but spent less time discussing the differences between each of the respective “Big 3.” When analyzing potential GPU-cloud returns on capital for each of the Big 3, I believe the analysis should be oriented around the factors listed below:
- Strength of Custom AI Accelerator Business – Google is in the strongest position with the TPU program by far the most mature. Additionally, the ability to sell AI Accelerators direct to customers (as with the recent 3.5GW Anthropic/Broadcom deal) produces incredibly high-margin revenue with virtually no incremental capital deployed – a tremendous boon to the economics of the collective Google Cloud business. AWS and Anthropic have announced multi-GW deployments (Project Rainier) and there are rumors of Anthropic also entering into a similar style arrangement with AWS to purchase Trainium/Graviton chips directly. Microsoft has by far the weakest custom chips business, with both its Maia AI Accelerator and Cobalt CPU programs significantly more immature than Google and Amazon’s franchises.
- Revenue Share Economics w/ Frontier Labs – Microsoft currently has the most attractive revenue share agreement with a frontier lab, as I estimate Microsoft (net of reimbursements for Azure OpenAI Services and Bing) is entitled to 10% of OpenAI’s 2025 revenue. Additionally, this revenue share is not contingent on Microsoft providing the compute capacity or the inference flowing over an Azure service (OpenAI Services, Foundry, etc.) – whereas AWS/GCP are only entitled to a cut of the revenue that they directly generate for Anthropic. However, the Microsoft agreement with OpenAI will likely evolve drastically once we reach “AGI” as defined by an independent expert panel, whereas AWS/GCP agreements with Anthropic (and AWS/OpenAI’s agreement for OpenAI Frontier) almost certainly do not have similar clauses. My guess is that at the appropriate time OpenAI’s deal with Microsoft will revert to a relationship similar to the Anthropic/AWS relationship (AWS entitled to a cut of the revenue
- Frontier Model Ownership – Google is pretty clearly in the lead with Gemini. Microsoft is now pursuing AGI independently of OpenAI (with access to their IP). AWS does not appear to be building a frontier model. Owning a frontier model, at scale, will allow the hyperscaler to capture all of the margin associated with selling tokens to enterprises. That margin is likely quite low/non-existent right now, but at some point the incremental contribution profit from selling tokens should scale over the semi-fixed costs of model training and research.
- Embeddedness in Traditional Compute Environments – AWS and Azure are deeply embedded in organizations traditional compute environment. Traditional hyperscale market share is likely indicative as to how much each hyperscaler should expect to benefit from the increasing utilization of traditional compute, storage, networking, and services.
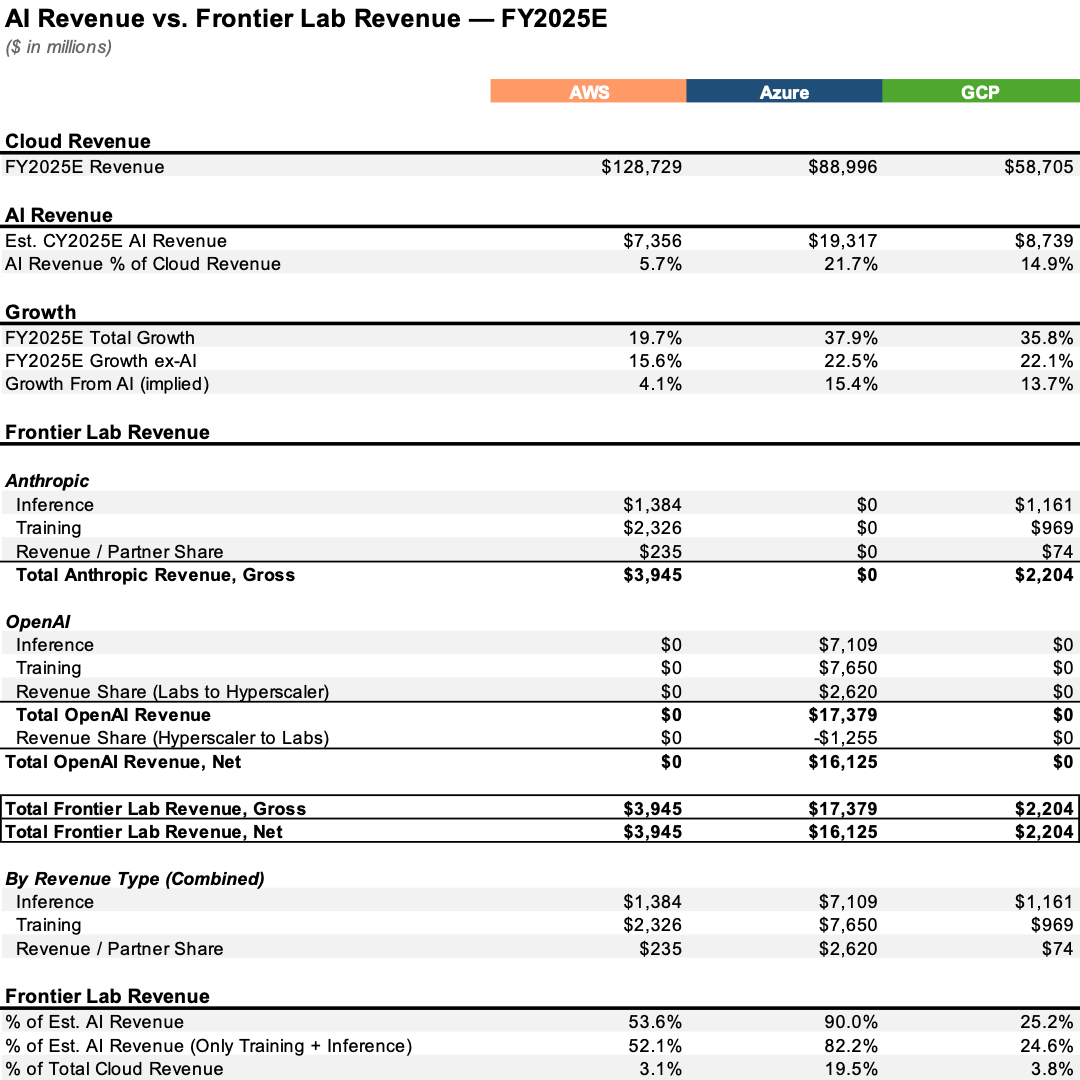
- Percent of AI Revenue Generated From Frontier Labs – It stands to reason that the larger the percent of a hyperscalers’ AI revenue is generated from frontier labs, the worse the economics will be (as frontier labs will have more bargaining power vs. enterprises). Below, I use estimates derived from publicly reported information to estimate (i) total AI revenue per hyperscaler and (ii) revenue allocations from each frontier lab to the respective hyperscalers. The upshot is that I believe ~80% of Microsoft’s 2025 AI revenue was attributable to OpenAI training and inference (excluding the revenue share), ~50% of AWS’s 2025 AI revenues were attributable to Anthropic training and inference, and ~25% of GCP’s 2025 AI revenues were attributable to Anthropic training and inference.
Sources
- Dan Sundheim, "The Art of Public and Private Market Investing," Invest Like the Best (Episode 460), February 24, 2026.
- Mostly Borrowed Ideas, "AWS: Pre and Post-ChatGPT," MBI Deep Dives (Substack), March 7, 2026.
- Industry conference transcripts and public-domain industry commentary, December 2025 – March 2026.
- Industry trade press coverage of GPU-cloud pricing and market dynamics, 2025–2026.
- Microsoft Investor Relations Dinner, Goldman Sachs TMT Conference, September 2025.
- Amazon Q4 2025 Earnings Call, February 2026.
- Andy Jassy, 2025 Amazon Annual Shareholder Letter, April 2026.
- Dylan Patel (SemiAnalysis), Daytona Compute Conference, March 9, 2026.
- Author primary research interviews with industry practitioners, October 2025 – April 2026.
- Sightline Climate, U.S. Datacenter Pipeline Tracker, March 2026.
- SynMax Vulcan / IIR Energy, Datacenter Delay Estimates, 2026. See also Financial Times, "US Data Centre Delays," April 2026.
- Maine LD 1895, "An Act to Place a Moratorium on the Construction of Large-scale Data Centers," signed into law March 2026. See also state-level tracker at robertbryce.com/rrdb for pending legislation in 10+ additional states.
- Robert Bryce, "AI Rejected: Tracking the Great Data Center Revolt," robertbryce.com/rrdb, 2026.
- Industry channel checks with data center contractors and operators, Q1 2026.
- Jensen Huang, interview with Dwarkesh Patel, April 15, 2026.
- Sell-side industry notes, various issuers and dates, 2025–2026.
- "Almost Half of Planned US Data Centers Face Delays or Cancellation," Bloomberg News, April 1, 2026.
- The Verge, reporting on internal OpenAI communications, April 2026.
- Jefferies, Proprietary CIO Survey (n = 30), March 2026.
- Piper Sandler, Proprietary CIO Survey (n = 80), December 2025.
- TD Cowen, Enterprise Software Spending Survey (n = 156), January 2026.
- Morgan Stanley, 1Q 2026 CIO Survey (n = 100), April 2026.
Important Disclosures. This post expresses the personal opinions of the author and does not represent the views, recommendations, or investment advice of any firm with which the author may be affiliated. It is provided for educational and informational purposes only and is not investment, legal, tax, or financial advice, nor an offer or solicitation to buy or sell any security or advisory service. The author and/or the author's affiliates may hold long or short positions in the securities discussed (including AMZN, GOOGL, MSFT, NVDA, AMD, CRWV, and ORCL, among others), and may buy, sell, or otherwise change those positions at any time without notice. Any analytical outputs (including IRRs, ROICs, valuation ranges, and forward-looking estimates) are hypothetical, rely on assumptions that may prove incorrect, and are not indicative of the results any investor has achieved or will achieve. Hypothetical performance has inherent limitations and does not reflect the impact of actual trading, fees, or market conditions. Third-party quotes and data have been paraphrased or summarized; readers should consult the original sources for full context. Past performance is not indicative of future results. Do your own research and consult your own advisors.