
AI Bubble? - The Bull & Bear Case
Introduction
September & October 2025 will go down as the months in which the AI infrastructure buildout entered a new, potentially more precarious, phase. A flurry of recent announcements provides a demarcation point. What began as hyperscalers deploying internal cash flows to build datacenter (DC) capacity has now morphed into an increasingly circular ecosystem of cross-investments, debt financing, and unprecedented capital commitments.
The numbers are staggering: OpenAI wants to spend $450B on compute through 2030 and claims it may need 250 gigawatts (GW) of capacity by 2033 – roughly 20% of current U.S. power production. Oracle just announced a $300B deal with OpenAI that would require ~$150B–$200B in capital expenditure against just $25B in EBITDA. Citi projects global AI infrastructure spend to reach ~$1.5 trillion by 2028.
This report examines a few critical questions:
- What's driving this explosion of circular deals between OpenAI, Nvidia, Oracle, and others? (Short answer: The hyperscalers don’t have the cashflow – as the required investment will exceed 100% of hyperscaler cash from operations by 2027)
- How much annual AI revenue must materialize to justify these investments? (Short answer: $1.1T+ by 2029)
- Are we witnessing the inflation of a bubble or the rational buildup of much needed infrastructure? (Short answer: Not clear. Looks like the seeds of a bubble have been laid, but it’s not clear we are at the peak yet)
- How should I respond as an investor? (Short answer: Understand the incentives of the major players, appreciate the scale of investment, be cognizant of the bull/bear arguments, appropriately assess single-stock risk and potential lurking portfolio exposures, diligence a shopping list, prepare to be rational in the face of potential lunacy)
It looks as if we're entering a period of capital deployment that increasingly resembles prior infrastructure bubbles: creative financing, circular dependencies, and a shift from cash-funded to debt-funded growth. Yet unlike pure speculative manias, genuine technological progress and economic value creation are underway, and there are legitimate reasons to believe that AI progress will continue scaling exponentially. In my opinion, the current question isn't whether AI will transform the economy, but whether the pace and magnitude of current investment are now disconnected from a realistic timeline for returns.
Recent Announcements
There has been a flood of recent announcements related to AI/data center partnerships. While it oversimplifies the situation to only focus on OpenAI, the situation can best be understood by appreciating that OpenAI is trying to reconcile the following facts:
- OpenAI wants to spend $450B on compute from 2025–2030
- Sam Altman has said OpenAI may need 250 gigawatts (GW) of compute capacity (~20% of current U.S. power production) by 2033 (est. cost = $6-12 trillion?)
- Recent projections have the company burning $115B of cash between now and 2029
Put simply, OpenAI burns tremendous amounts of cash from simply renting compute capacity, but its plans require someone fronting trillions of dollars of capex over the next few years.
For reference, OpenAI hopes to end this year with ~$20B of ARR and ~2.5 GW of capacity. And while OpenAI pays ~$10–12B a year to rent one GW of capacity, someone needs to spend ~$35B of capex to bring each incremental GW online.
It’s important to digest the following announcements in light of the above facts.
Oracle / OpenAI Deal
On September 9th Oracle released FQ1 2026 earnings and disclosed a remaining performance obligation (RPO) of ~$450B vs. analyst estimates of ~$150B. Additionally, management gave Oracle Cloud Infrastructure (OCI) revenue guidance of:
- $18B for Fiscal Year 2026 (ending 05/31/2026)
- $32B for FY 2027 (updated to $34B post October 16th Oracle Analyst Day)
- $73B for FY 2028 (updated to $77B)
- $114B for FY 2029 (updated to $129B)
- $144B for FY 2030 (updated to $166B)
For reference, OCI’s FY 2025 revenue was $10B, Google Cloud’s estimated calendar year 2028 revenue is $113B, and AWS’s 2025E revenue is $142B. Oracle expects to 14x its current cloud business, potentially leapfrog Google into 3rd place in the cloud market, and do in ~4 years what it took AWS 10 years to do (go from $10B of revenue to $165B+ of revenue).
Days later it was reported that Oracle and OpenAI signed a $300B five-year cloud deal (the entire delta between analyst estimates and Oracle’s reported RPO). OpenAI had previously announced that the deal with Oracle was for 4.5 GW of capacity.
This is an incredible amount of capacity. For perspective, numerous industry sources (Bernstein, SemiAnalysis) and my calculations indicate that it currently requires ~$35B+ of capex to bring 1 GW of AI DC capacity online. This indicates Oracle is planning to spend roughly ~$150-200B of capex over the next 5 years (vs. FY 2025 EBITDA of ~$25B, slightly negative FCF, and capex of a little over $20B).
Also, it’s worth noting that Jensen Huang has repeatedly stated that Nvidia gets about ~$35B of revenue from each $50B of DC investment. While it’s not a foregone conclusion that Nvidia will be the chip supplier for 100% of this capacity, it is likely that this deal benefits Nvidia revenue to the tune of $100B+ (~$175B capex * 70% to Nvidia = $105-$140B, assuming no leakage to AMD/ASICs/etc.).
Nvidia / OpenAI Deal
On September 22nd, Nvidia and OpenAI announced a strategic partnership to deploy 10 GW of Nvidia systems in the coming years. The structure of the deal is that Nvidia will invest $100B into OpenAI progressively as each GW comes online ($10B after 1 GW, another $10B after the second GW, etc.). Each subsequent cash infusion will be at OpenAI’s “fair market value” at the time of investment.
From OpenAI’s perspective, this helps provide the company with the necessary cash to fund its compute ambitions. However, it is worth noting that Nvidia will only be providing ~30% of the necessary financing for each GW of capacity ($10B of the ~$35B). OpenAI will need to find other financing partners for the remaining $25B necessary to bring each GW online.
This deal seems to make a lot of sense from Nvidia’s perspective. Nvidia will provide $10B per GW of capacity, but each GW of capacity will eventually produce ~$25B of revenue for Nvidia. At Nvidia’s 75% gross margins, this will produce $19B of gross profit vs. $10B of investment. Additionally, this $10B isn’t truly “spent.” It’ll be invested into OpenAI, which Jensen has said he expects to be the next “multi-trillion-dollar hyperscale company.
This investment also strengthens one of Nvidia’s primary customers, and its $10B worth of funding lends credibility to OpenAI when approaching outside parties for the additional ~$25B per GW.
It should also be noted that Jensen made clear that this investment is for “OpenAI’s own self-build,” implying that this is separate from their agreement with Oracle. This is for OpenAI to build owned-and-operated capacity.
CoreWeave Deals w/ Nvidia & OpenAI
On September 15th CoreWeave announced a $6.3B order with Nvidia. Nvidia guaranteed that it will purchase any capacity not able to be sold to customers. 10 days later, on September 25th, CoreWeave announced an expanded agreement with OpenAI. As part of the agreement OpenAI will commit to rent $6.5B of compute capacity from CoreWeave in the coming years.
Although the numbers are similar, note that these aren’t apples-to-apples numbers. One is a stock ($6.5B of Nvidia system capex, which likely represents a ~$10B datacenter buildout) and one is a flow ($6.3B of revenue from OpenAI over a number of years).
AMD / OpenAI Deal
On October 6th OpenAI and AMD announced a partnership to deploy 6 GW of AI compute capacity in a massive infrastructure push. As a part of the deal OpenAI will receive 160M AMD penny warrants, with earnouts based on GW deployment and share price targets (the last tranche is earned at $600/sh. vs. a pre-deal price of $164/sh.). The warrants work out to ~10% of AMD’s equity value – representing ~$27B of value before the deal was announced and $34B post-deal announcement.
6 GW of AMD compute implies ~$150B of total spend, which likely translates to $80B+ of revenue for AMD in the coming years (slightly lower conversion rate due to a lower revenue share of networking vs. Nvidia).
[Note: I calculate Nvidia DCs cost $35B/GW to bring online and AMD-filled DCs cost ~$25B/GW to bring online.]
Broadcom / OpenAI Deal
On October 13th OpenAI and Broadcom announced a collaboration for 10 GW of custom AI accelerators. OpenAI will design the chips and systems, which will be developed and deployed in partnership with Broadcom.
Circular Financing Loop
At this point, the relationship between Nvidia (and AMD to some extent), OpenAI, and the leading “neoclouds” is becoming fairly incestuous.
Effectively, Nvidia is using its pristine balance sheet and prodigious cashflow to buy equity from OpenAI/backstop CoreWeave. OpenAI then signs deals with Oracle and CoreWeave, giving revenue to the neoclouds. Oracle and CoreWeave’s market caps expand due to strong backlog growth/being perceived as “AI winners.” They take the money from OpenAI + debt-financing (because they’re AI-winners so why wouldn’t people lend to them) and give it to Nvidia by buying more chips. Nvidia then uses that money to invest in OpenAI/backstop CoreWeave, bringing us back to the beginning.

The scale of investment is getting so large that outside capital partners are now required. For example, Meta was recently in talks with Apollo, Brookfield, Blue Owl, and PIMCO for a $29B financing package for datacenter investments (ultimately partnering with PIMCO for $26B of debt and Blue Owl for $3B of equity). xAI is looking for a similar deal to finance a $20B data center with $12.5B of debt and $7.5B of equity. Nvidia has committed to $2B of equity financing for this xAI DC (but those funds are conveniently earmarked to buy Nvidia chips).
OpenAI will need $800B-$1.1T of total capital to bring 26 GW online under its Nvidia, AMD, and Broadcom deals (which definitionally are mutually exclusive). Oracle will be unable to afford its ~$150-$200B 4.5 GW buildout using internally generated cash alone. As of now, it’s not yet clear where all of this capital is going to come from.
Roles & Incentives Of Key Players
Below I am highlighting my perception of what the key players’ incentives are with respect to the above (and potentially future) deals:
OpenAI (The Initiator)
As previously discussed, OpenAI’s primary goal is to secure the massive, ever-growing compute capacity needed to train its frontier models and serve its rapidly growing consumer and enterprise business. However, it is cash poor relative to its ambitions and must offload the capex to partners. OpenAI’s incentives are to lock in long-term compute capacity at the best possible price while avoiding the up-front capital requirements, while making itself central to the AI ecosystem (“too big to fail”) in the process. Additionally, OpenAI is seeking to diversify its partner base to reduce reliance on Microsoft and Nvidia, while simultaneously not overly agitating them (because they will continue to be reliant on both for the foreseeable future).
Nvidia (The Kingmaker)
Nvidia’s dominant position in the GPU market makes it the primary beneficiary of the AI DC buildout. Historically, Nvidia has leveraged its position to prioritize GPU allocations to neoclouds, in order to reduce their customer concentration with the legacy hyperscalers. However, with power now becoming the bottleneck (whereas it was GPU allocations previously), Nvidia is using its pristine balance sheet and prodigious cashflow to directly finance and backstop its partners. They hope to ensure demand for its hardware by financially supporting its most aggressive customer (OpenAI investment) while seeding a competitive ecosystem beyond the incumbent hyperscalers (CoreWeave backstop, “OpenAI the next hyperscaler”).
Oracle & CoreWeave (The Challengers)
These companies perceive a once in a generation opportunity to make a levered bet that AI-workload demand is going to persistently exceed incumbent hyperscaler forecasts. These companies are risking building tens of billions of dollars of infrastructure for a counterparty that has no balance sheet and currently burns significant amounts of cash (OpenAI) in an attempt to become the fourth and fifth hyperscalers. Both hope that the AI ecosystem remains in a supply constrained environment, and by being the most aggressive in procuring additional compute capacity, they’ll naturally take market share as their provisioned capacity becomes available and industry DC utilization hovers above 90%.
Microsoft & Amazon (The Incumbents)
The established leaders (Azure and AWS) have large, profitable cloud businesses to protect. While they are investing heavily in AI, they are more risk-averse and disciplined with capital. They have witnessed frontier lab cash burn firsthand (OpenAI/Anthropic) and appear unwilling to single-handedly finance the most ambitious, speculative build-outs. They want to maintain their market leadership by investing at a pace they deem sustainable, funded primarily by internal cash flow. They are balancing the need to capture the AI opportunity while not massively overbuilding. Their reluctance to fully fund OpenAI's requests created the opening for challengers like Oracle.
AMD & Broadcom (The Diversifiers)
OpenAI's deals with these companies reflect its (and the market's) desire to mitigate its deep reliance on Nvidia and its ~75% gross margins on GPUs. For AMD, this is an opportunity to establish itself as a viable competitor in the high-end AI accelerator market. For Broadcom, it's a chance to leverage its custom silicon (ASIC) capabilities.
Alphabet (The Catalyst)
In many ways, the cross-dealings between OpenAI (the consumer app/model layer), Nvidia (the chip layer), Oracle (the hyperscaler), and Nvidia + the Alts (cheap access to capital) is all an attempt to compete with Alphabet. They have the integrated stack – the widest reaching consumer facing business in the world, the most advanced compute architecture, the most-powerful and most efficient models in the world, a rapidly growing hyperscale business & enterprise salesforce, and a lower cost of capital than virtually anyone else. As I mentioned earlier this year – the more this becomes an arms race, the more this advantages Google. The market (and Google’s competitors) are finally waking up to this.
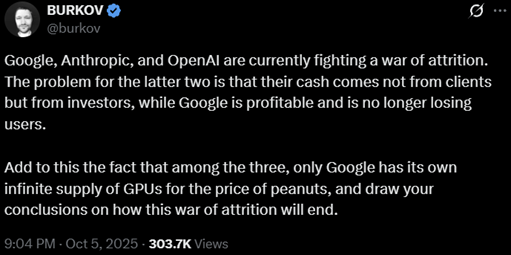
The Size of The AI Datacenter Buildout
Below I am attempting to highlight the magnitude of the current AI DC buildout roadmap.
- The below chart shows Citi’s estimates for Hyperscaler capex and Global AI Infra. capex
- $490B / $575B / $635B U.S. hyperscaler capex for 2026E / 2027E / 2028E
- $600B / $900B / $1,480B Global AI-related capex for 2026E / 2027E / 2028E
- Exhibit 4 shows a bottom-up hyperscaler capex estimate from SemiAnalysis
- $505B / $610B of hyperscaler capex by 2026E / 2027E
- Doesn’t include xAI or OpenAI owned-and-operated (O&O) builds
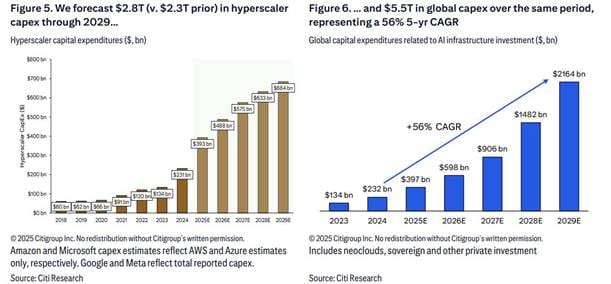
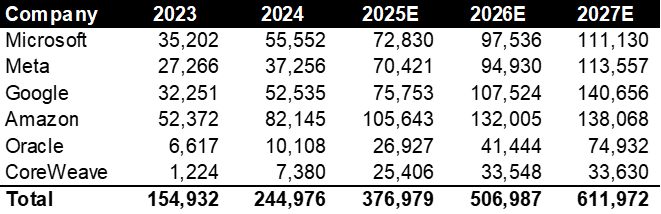
The size of the DC buildout to date has been so large that one Harvard economist estimated that H1 2025 US rGDP growth would’ve been ~0.1% without it. To be fair, I’m not sure he accounted for the fact that the import of semiconductors and related equipment has provided an offsetting headwind to GDP (as imports reduce GDP), however, I think the point stands. The amount of capital being mobilized is astounding.
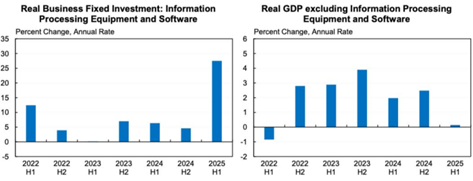
This is all on a 2025 amount that’s expected to be ~50% of the 2028 build. $700B of potential US DC investment by 2027 would work out to ~2.2% of GDP.
For reference, the telecom boom of the 90s reached ~1.5% of GDP and the electric motor (1920s) and US auto manufacturing booms (1910s) both barely eclipsed 2.0%. The only historical comps (pushing well above 2%) were the UK Railroad buildout (~4.5%) and the US railroad buildout (~3.5%). We are heading towards rarified air.
Noah Smith recently wrote a blog post summarizing a few different pieces of reporting along the same lines titled “America's future could hinge on whether AI slightly disappoints.”
The Odd Lots newsletter recently addressed a tangential issue in a post titled “AI Turns the Cyclical into the Secular,” discussing how a classically cyclical company like Caterpillar (which recently hit an all-time high) has turned into a secular winner due to one of its lesser-known products, power-generation turbines.
My own portfolio possesses some non-obvious correlations with the data center buildout. Recent channel commentary from Ferguson highlights that a significant amount of recent volume comes from datacenter related spend (“if it’s not a data center, it’s not being built”). Apollo will likely provide funding for tens of billions of data centers by the time it’s all said and done. United Rentals bread-and-butter is “mega-projects” and DC builds are almost certainly driving higher utilization and rate across its portfolio. The aggregates players (Vulcan and Martin Marietta) are also benefitting, as strengthening non-residential spend is offsetting a weak housing environment.
It's tempting to think cleanly of the hyperscalers, semis, and semicap as “long AI” bets and software as synthetic “short AI” exposure. However, the degree of spending is so large now, reaching so deeply into many other sub-sectors of the economy, that I don’t think it’s an oversimplification to argue that near/medium term growth for many sub-sectors of the economy is reliant on continued strong AI capex.
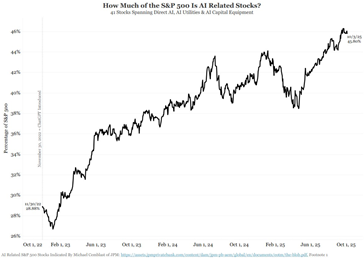
From an equity market perspective, JPM’s Michael Cembalest recently put out a note highlighting that 41 stocks spanning Direct AI, AI Utilities, & AI Capital Equipment make up ~45% of the S&P 500’s value. Now, while not 100% of the enterprise value of every single one of these businesses is derived from “AI,” I believe the point stands that the AI investment cycle has reached such scale that it is virtually impossible to have a view on the U.S. stock market (or economy for that matter) without having a short-to-medium term view on AI progress and the associated DC buildout.
Required Revenue
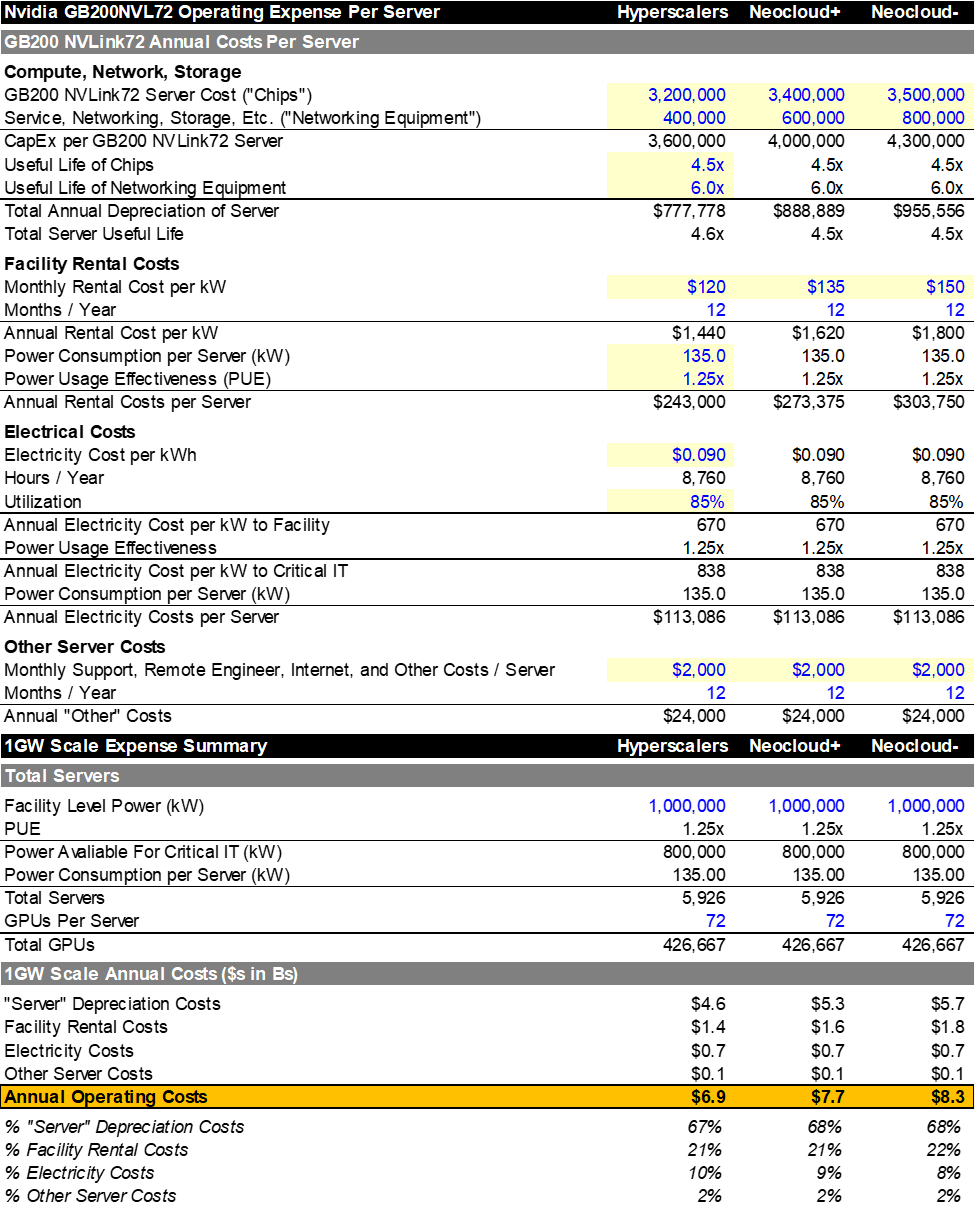
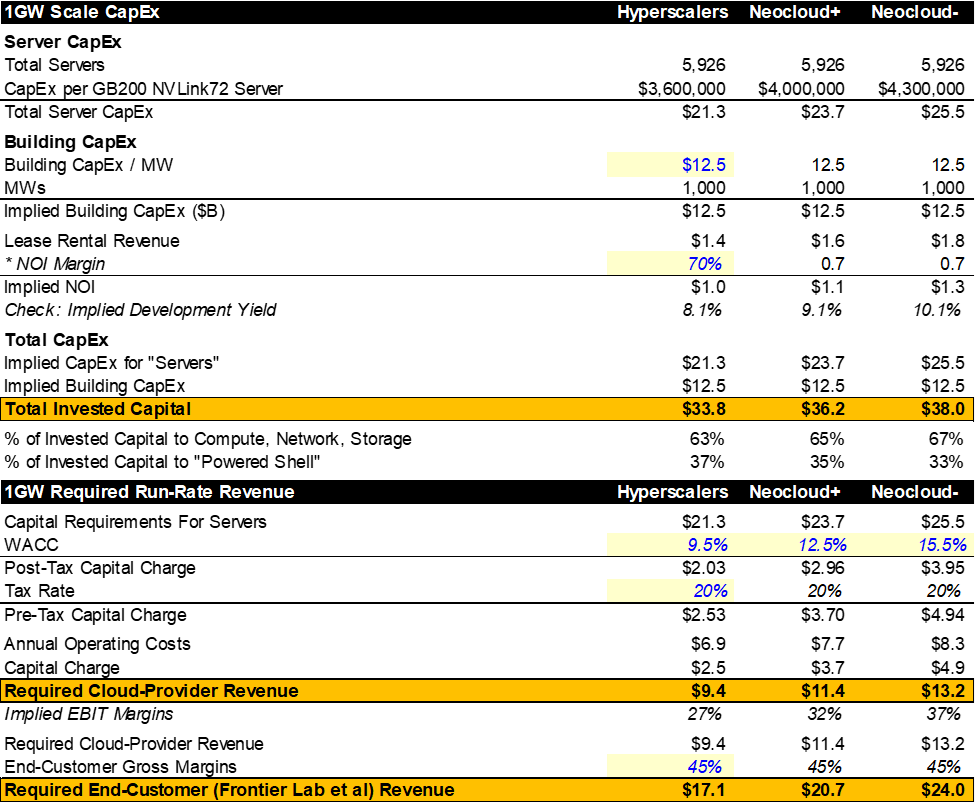
Eventually, these investments must earn an economic return. While the hyperscalers are almost certainly estimating returns using a cashflow/IRR approach for each MW of capacity they plan to bring online, we can make some straightforward assumptions regarding the totality of spend that give us the implied run-rate of end-customer revenue that each GW capacity needs to generate.
Below, I’ve broken Exhibit 7 into four sections:
- Estimating the per server operating costs of a new Nvidia GB200NVLink72 server
- Scaling these “per server” operating expenses up to a 1 GW level DC
- Estimating the invested capital (server + building capex) required for 1 GW of capacity
- Calculating the required cloud-provider revenue to earn a fair cost of capital & required end-customer revenue (assuming a certain level of gross margins for those customers)
My base case is that 1 GW of capacity:
- Costs $34–$38B to build (capex)
- Produces $7-8.5B of annual opex (including depreciation)
- Requires the cloud-provider to earn $9.5-13B of revenue
- And needs to generate ~$17-24B of annual revenue for the end customer (frontier AI labs, SAAS app using inference tokens, etc.) assuming GMs of 45% for the end-customers
[Note: There is some debate as to whether capex/GW is ~$35B or $50B (as Jensen Huang has repeatedly said it costs $50B, but most other industry checks suggest ~$35B. Ultimately, this is a complex question because it depends on whether “1GW” is being used to describe the IT load to the facility or to the critical IT. Additionally, with power being the primary constraint, some industry participants have started engaging in “power oversubscription,” where they simply assume that the critical IT equipment will never operate at 100% capacity, allowing them to fit more chips into a DC. For example, I assume a 1GW facility can fit ~6,000 GB200 NVL72 servers, but it’s believed some participants are fitting ~8,000+ servers inside of a “1GW” facility, estimating they’ll never draw max power. Ultimately, I feel very comfortable with my $35B/GW est.]
Importantly, each year’s “capex cohort” needs to generate its own run-rate revenue. And as the numbers get larger, the total revenue needed from each successive cohort stacks on top of previous cohorts. Below I am modeling US DC capex of $375B, $500B, $600B, $650B, and $700B for 2025 – 2029 respectively. Each of these “capex cohorts” needs to generate their own run-rate revenue profiles that stack on top of each other. Allowing each cohort ~3 years to reach maturity, I estimate that we’ll need revenue of ~$1.0T+ by 2029 to earn an appropriate return on this investment. Even under a more conservative scenario (assuming each GW of capacity only needs to earn $15B of revenue to justify continued investment), we’ll need ~$831B+ of revenue.
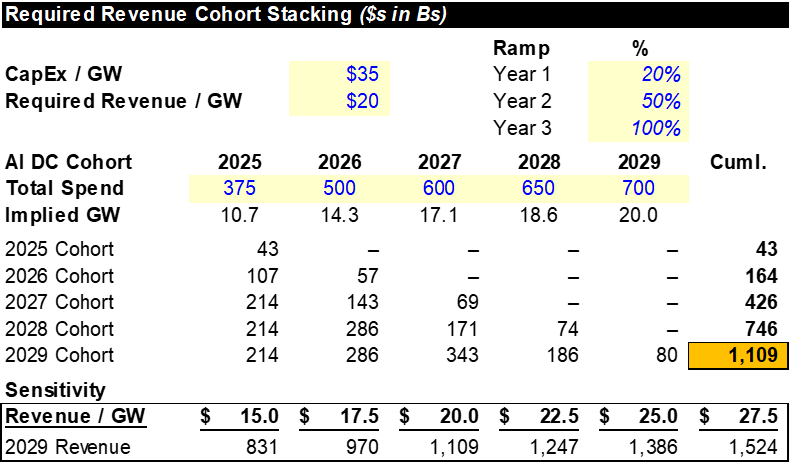
A few things worth noting:
- Some hyperscalers may be willing to accept lower ROICs because this is likely to be an iterative game where accepting lower returns on the first cohort of AI DCs allows you to build the customer relationship and earn higher returns on later cohorts
- End customer gross margins of ~45% are low compared to software (70s) or PaaS (60s), however, some businesses (OpenAI, Anthropic) may be willing to accept lower all-in gross margins if GMs excluding training (so only burdened by inference) remain healthy (for reference, Anthropic/OpenAI currently earn 0%/-10% GMs burdened by training costs, but 60%/50% GMs when only counting inference COGS)
- While I’ve oversimplified the situation by only denoting required AI revenue, what this investment really needs to produce is dollars of economic value. That can take the form of revenue added or costs avoided (a.k.a. internal efficiency gains)
Bull Case
Below I’m summarizing what I believe are the best arguments as to why we are not in a bubble and why the rapid pace of investment can continue. To be clear, I am steel-manning the case. I believe this is important to do, as I’ve recently seen several critiques that simply dismiss the investment due to the sheer magnitude alone.
Rapidly Growing Economic Value
While in Exhibit 8 I estimate that AI capex will need to generate $1.0T+ of economic value by 2029 to provide an adequate return, I only estimate that the 2025 “capex Cohort” needs to generate $45B of economic value in 2025. Even if we increase that amount to $60B to account for some of the capex spent in prior years, we are clearing that hurdle to date. OpenAI and Anthropic are going to end the year with ~$30B of ARR, a host of SAAS apps are responsible for another few billion. Google, Meta, and Amazon alone have $500B+ of advertising between them and have been calling out AI-related ROAS improvements. Mid-single-digit ROAS improvements equal tens of billions of dollars of value annually to the digital ad players.
Additionally, the revenue growth rate of the frontier labs is staggering. Anthropic is projecting to more than double ARR from $9B at YE 2025 to $20B YE 2026. A business that had no revenue a couple of years ago is going to produce as much revenue as BlackRock or Sherwin Williams by 2026. It’s hard to fathom the magnitude of revenue growth.
Latent Utility & Productivity Enhancements
AI-adoption is unlike anything the world has ever seen before, and the consumer surplus is massive and difficult to quantify. How much should everyone in the world be willing to pay to have a graduate-school level polymathic digital assistant in their pocket? If 3B people were willing to pay $10 a month, that’s $360B of annual revenue. For reference, estimates place Meta’s US ARPU at ~$30 a month.
It's often argued that even if AI-progress were paused, we likely have years’ worth of economic value to be captured via modernizing legacy workflows alone. Numerous academic studies and company anecdotes show that AI Adoption is driving increased labor productivity in narrowly defined repetitive tasks.
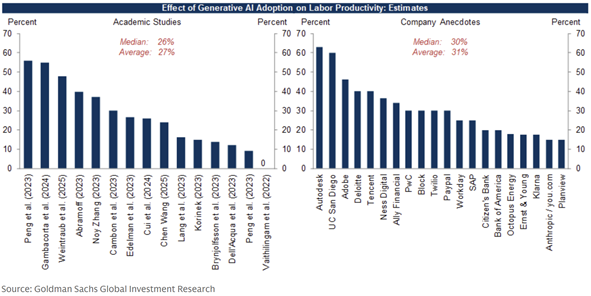
For example: Software development is a ~$2.5T market. Customer operations is a ~$800B market. Legal services is a ~$1.0T market. Pharma/Chem/Materials R&D is a ~$400B market. Marketing and sales is a ~$750B market. When you add these up, there’s probably $3-$5T of spend in markets that are “highly addressable” by AI. Can AI drive a 15% improvement in productivity? If so, that’s $600B in value.
Flurry of Announcements = Incremental
Capacity additions to the extent of the announcements outlined above are not in consensus numbers. If everything discussed ends up getting built, sell-side AI capex estimates will likely need to rise further.
Scaling Laws Holding & Agentic Time-Horizons Expanding
“Scaling laws” simply refers to the observable phenomenon that model test loss (aka error rate) falls as a smooth power law when you scale one of three knobs: compute, data, and model parameters. All else equal, an increase in any of those three inputs will result in a reduction in test loss – therefore, a better model (Exhibit 11).
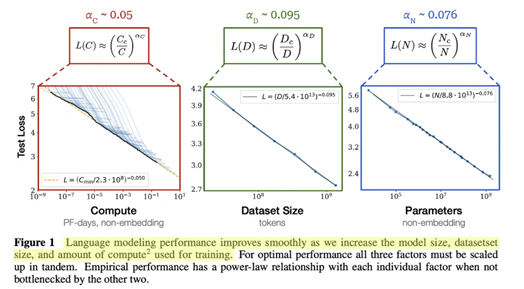
While “scaling laws” previously were only used in reference to pre-training, we now are able to scale along multiple vectors: pre-training, post-training, and test-time compute.
- Pre-training: The initial phase where a model learns from vast amounts of data. You’re essentially teaching the model statistical patterns of the training data. This has historically been the most expensive phase. You’re basically building the model’s foundational capabilities
- Post-training: After pre-training, you refine the model through reinforcement learning (RL) and other alignment methods
- Test-time compute: Instead of a model giving an immediate response, the model can “think longer” on difficult problems – spending more computational resources during inference to verify its own reasoning or try multiple approaches to a task
The bull case is that while we have been mostly scaling via pre-training up until late 2024 (introduction of reasoning models), we now have two new vectors upon which to scale, potentially accelerating model improvement.
The introduction of reasoning models has resulted in an “inference explosion,” with token usage inflecting materially higher for virtually all AI companies. It’s possible that we’re still in the early innings of recognizing the benefits of test-time compute scaling.
And historically, “post-training” was a relatively resource light task where fine-tuners basically made sure the models were “safe and aligned.” Now, however, there has been a major push to build out “RL gymnasiums” at the frontier labs. These gymnasiums basically mimic common computer/software environments such as Salesforce, Amazon.com, Microsoft Outlook, Jira, common websites, etc. The goal is to teach these models (via agents) how to operate within these environments. The hope is that by training these agents to use common software products, they’ll better be able to (i) provide economic value by assisting within these commonly used tools and (ii) generalize about how to use a computer. Many large applications have been opting into the Anthropic backed “Model Context Protocol,” which is a protocol that helps LLMs talk and work with external systems (like Shopify, Spotify, Google Maps, Uber, Airbnb, databases, payment rails, etc.) in a standardized way. As the industry moves to create protocols like MCP that allow LLM agents to work with applications, and RL gyms help models generalize towards computer use for the long-tail of applications that don’t use MCP, we could be quickly moving towards a world in which AI agents can use a computer to do large swaths of white-collar work.
[Note: If struggling to grasp the concept of an “RL Gym,” the two best explainers I’ve ever seen on reinforcement learning are videos showing the process of teaching a computer to play Pong (simple) and to play Pokemon (more complex). Imagine the same “reinforcement learning with verifiable rewards” approach being used to teach an agent how to complete a checkout on Amazon.com or to qualify a sales lead in Salesforce.]
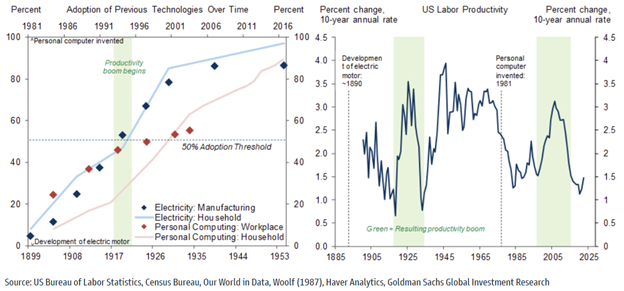
While it’s difficult (quasi-impossible) as someone not working at a frontier AI lab to observe in real-time if scaling laws are holding, we do get hints as incremental models are released. Below I am showing a chart from METR that tracks the ability for AI models to work uninterrupted on a task (note log scale). While not a direct measure of the inputs (parameters, compute, data) needed to truly compute scaling laws, I’d argue the below chart is a fair output-based observational method of determining whether or not scaling laws have been holding up.
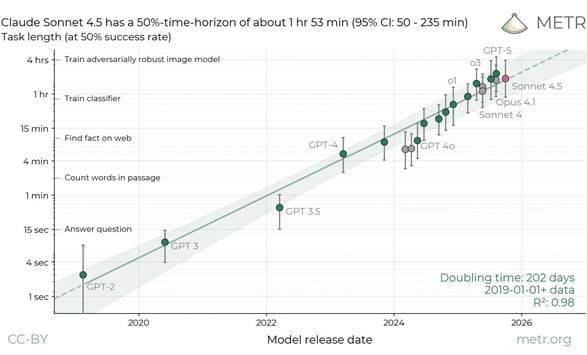
ChatGPT 5 and Sonnet 4.5 are the most recent releases, and both can work on a task uninterrupted for ~2 hours (see methodology here). This gets to the heart of the AI “mega bull” case summarized by the “AI 2027” project team. Essentially, if we continue to get a doubling of agentic time horizons, we are quickly going to get to the point where AI itself can help out with AI research. To date one of the primary bottlenecks is the limited number of frontier AI researchers. It’s often said that there are only a thousand or so people in the world that have the training, intelligence, and intuition to do this type of research (note the NBA-sized pay-packages for machine learning PhDs). But if METR’s observation of agentic time-horizons doubling every ~200 days holds… we could be looking at a near infinite number of AI researchers able to work by themselves for days at a time by 2028 (and months at a time by 2030) – this is before accounting for any acceleration to the trend due to the fact that an agentic AI researcher that can work ~16 hours by themselves may very well increase the pace of AI research (shortening the 200-day doubling timeline).
In fact, many speculate that this is one of the reasons that Anthropic has been so focused on coding, as scaling coding forces the model to reason over strict syntax, call tools, manage state, and execute multi-step plans – exactly the muscles agentic “AI researchers” need.
So, finally this year is where the compute supercycle is beginning properly… People have said that we've been hitting a plateau every month for the last three years… I look at how these models are produced and every part of it could be improved so much… It's a primitive pipeline held together by duct tape and the best efforts and elbow grease and late nights, and there's just so much room to grow on every part of it. I think it’s worth crying from the rooftops - anything that we can measure seems to be improving really rapidly… Bet on the exponential. – Shoto Douglas, Anthropic Researcher (10/2/2025)
The Weird Financing Agreements Are Recent
To date, the data center build out has been financed by the cash from operations of the hyperscalers. CoreWeave and some of the other neoclouds rely on debt-funding, but the majority of this buildout has been funded via hyperscaler cashflow. Technically, they haven’t even “used their balance sheets,” as the hyperscalers continue to have, in aggregate, net cash positions.
My read of the announcements/weird financing arrangements is that as we look forward to the buildouts that OpenAI wants for 2026/2027, the dollar amounts will begin to exceed the cash from operations of the hyperscalers, and while everyone remains “supply constrained,” much of the requested supply as we head into the back half of this decade is from OpenAI who currently doesn’t have the cash to pay. The legacy hyperscalers (Azure/AWS) are unwilling to lever-up to further accelerate buildouts. Enter the weird financing arrangements.
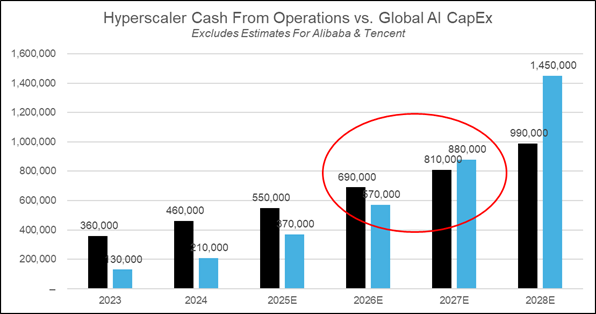
While the introduction of weird financing arrangements is often a precursor to a bubble, to date, this buildout has been cash funded. Since when does a bubble pop the month the scaled financial engineering gets introduced?
High Variable Costs of Development
One of the significant contributing factors to the telecom bubble of the early 2000s is that there were high fixed costs to deploy incremental fiber, but very low variable costs. The expensive part was the civil works – digging the trench, laying ducts, obtaining permits, etc. The fiber itself was very cheap by comparison. So, if you’d already dug the trench, you might as well drop a lot of fiber in there. This phenomenon helped lead to fiber overcapacity.
Conversely, the “fixed cost” side of the AI DC buildout is relatively low by comparison. A data center’s “powered shell” is ~35% of the project cost, with the majority of capex supporting chips and networking gear that depreciate over a ~4-6 year useful life. There is very little “this will be useful eventually” logic at play with the DC buildout. The vast majority of capital is put to work for assets that need to have a relatively quick payback period to justify the investment. This is the exact opposite of the fiber buildout and likely disincentivizes over-building.
Macroeconomic Accelerants
We are about to stimulate the U.S. economy using the two primary mechanisms:
- Monetary Policy – Per market implied expectations, the Fed Funds rate is expected to drop from 4.10% at present to ~2.85% by the beginning of 2027. Non-recessionary rate cuts are stimulative and inflationary
- Fiscal Policy – The OBBB will be highly stimulative over the next few years (estimated tailwind to GDP of 90bps, 60bps, and 30bps in 2026/2027/2028). Additionally, most servers and power/cooling units in an AI DC are subject to bonus-depreciate at 100%
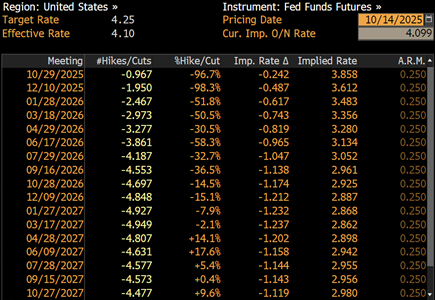
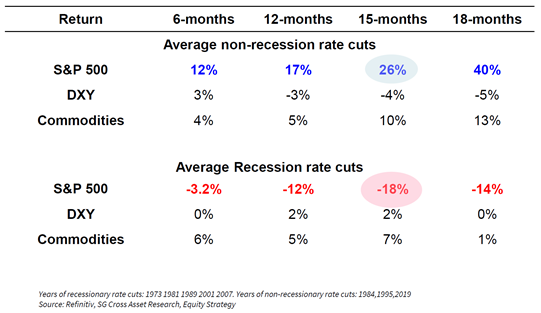
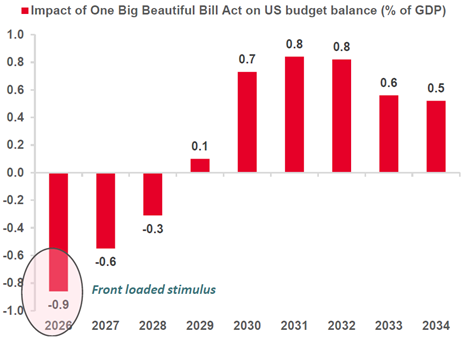
While markets are always forward looking (and it is difficult to know what is priced in), from a fundamental perspective, it looks as if the “punchbowl” is just getting set out.
Bear Case
Below I am arguing the bear case for AI progress and returns on AI DC investments. Again, this is my version of the steel man.
The Required Revenue Problem
This bear argument is straightforward. As shown previously, we likely need $1.1T+ of AI-related value add by 2029 and we’re going to end the year with $20B of OpenAI ARR, $9B of Anthropic ARR, and maybe another $5-6B of ARR tied to Microsoft Copilot, Gemini Pro, SAAS Agents, etc. Put it all together and we’ve got $35B? A far, far cry from a trillion. We need orders of magnitude more revenue to justify this investment.
For reference, the cloud IaaS market, which is now ~19 years old, produced $225B of revenue in the trailing twelve months ended June 30th, 2025. For AI revenues to reach ~$1.1T by 2029 we need revenues to scale ~5x as large over a 5x shorter time horizon – so basically 25 times as fast as the hyperscale cloud business model grew. Now, this ignores cloud PaaS & SaaS revenue. But comparing the size of the IaaS TAM to “required-AI revenue” highlights that the required pace of economic value-add is very fast.
ChatGPT is a wonderful product and provides tremendous amounts of value, but to justify the pace of investment we will need multiple killer apps (agentic shopping, major advancements to the software development life cycle, the multi-modal “AI personal assistant”) in a short order of time. Even with the significant utility/consumer surplus, until we have a more robust monetization mechanism, it’s going to be incredibly difficult to produce the revenue necessary to justify this investment.
Where Is The ROI To Date?
Measurable “AI ROI” for enterprises has proved elusive to date. Recently, MIT released a “State of AI in Business 2025” report highlighting that while AI adoption is high, only 5% of companies see measurable P&L impact. This report matches my anecdotal experience – outside of chatbots and coding agents, we aren’t seeing many “killer apps” in the enterprise.
Even with coding agents, probably the best example of LLMs finding product-market fit, I’m hearing of ~10-15% improvements in developer productivity because “writing code”, the part LLMs excel at, is only a small part of the multi-staged software development life cycle.
“We have a large business unit where we've had AI programming tools in place for a year. And we've certainly seen significant increases in the number of lines of suggested code over that period of time by the AI. And the percent of lines adopted has stayed pretty stable. But if we look at the actual programming efficiency, it's almost entirely flat. And so it isn't a panacea, we aren't always going to get enormous increases in programmer productivity in this large business unit, it is an example.
Now we haven't used a programming – having used programming agents in this particular instance. So, we've been using fairly simple tools, and we are moving to the next stage and trying out agents that are much more sophisticated and we'll see. There's a couple of other instances where we're seeing overall efficiencies in the 10%, 12% region. And as you may have heard, Google has reported something similar.
But there are also instances where we do see some very significant improvements. But those will be through the full life cycle of maintenance and support, whether those will be maintained is yet to be seen.” – Mark Leonard, Founder & President of Constellation Software (9/22/2025)
In fact, METR performed a randomized control trial to understand how early-2025 AI tools were affecting the productivity of open-source developers using AI tools and found that they were less efficient when using AI tools (taking 19% longer to complete a set of tasks), even though they thought they were faster (casting doubt on some other “self-reported” efficiency gain estimates). To be clear, the 16 engineers were expert engineers, deeply familiar with their open-source projects, mostly had not used Cursor/other agentic IDEs, and were using early-2025 models. This isn’t necessarily analogous to a less technically talented engineer, deeply familiar with Cursor, working on an unfamiliar codebase using Sonnet 4.5 (who would likely see productivity gains).
I recently asked multiple private equity firm partners if they could give me any tangible results from AI pilots to date and their answer was collectively “we’ve yet to witness any material hard dollar ROIs.” Informatica (a cloud software firm) made similar comments to The Information as part of a longer piece of reporting highlighting a lack of ROI from Microsoft Copilot. Chamath Palihapitiya has bemoaned the fact that his AI software development company 8090, which offers to rebuild enterprise software with 80% feature-equivalence for ~90% less than incumbents, isn’t catching on with PE-backed companies (even after warm introductions to “all the big, major” PE firms and their portfolio companies). In his telling, the “partners love it,” but the middle managers (“C” and “D” players) are blocking it/refusing to engage (it’s also very likely that the pros simply do not outweigh the cons of trying to recreate system-critical enterprise software on a budget).
Now, there is countervailing data that indicate AI adoption is driving increased labor productivity (see Exhibit 9 above). However, I’m skeptical of both general company anecdotes and the average academic study. Personally, I’ll want to hear of/see discrete financial line-item optimizations before getting too excited about AI ROI. So far, very few businesses have been able to point to expense leverage driven by “AI-cost-takeout” or revenue acceleration driven by a higher pace of product development.
This prior is supported by the fact that the history of technological innovation has been one of slow economic diffusion. Since the industrial revolution we’ve had major technological breakthroughs such as the steam engine, railroads, the telegraph, refrigeration, automobiles, airplanes, modern electricity, radio and television, the transistor, computers, the internet, and smartphones. However, with each of these it is quite difficult to identify any step-function changes on a long-term graph of GDP growth.
Additionally, labor productivity enhancements have often lagged technological breakthroughs by many years. It simply takes time for technological innovations to diffuse. Put simply, things are often quite more difficult than they first appear (see Andrej Karpathy quote below). One can be bullish long-term yet feel that the size and pace of the current investment require a requisite pace of return on that investment. There is likely a significant amount of process inertia (“this is the way we’ve always done things,” concern around job risk, data/access/trust issues, regulatory concerns, and other “change management” issues that act as a non-tangible, but still very material impediment to rapid AI adoption in enterprises.
Dwarkesh Patel –
“You’ve talked about how you were at Tesla leading self-driving from 2017 to 2022. And you firsthand saw this progress from cool demos to now thousands of cars out there actually autonomously doing drives. Why did that take a decade? What was happening through that time?”
Andrej Karpathy –
“One thing I will almost instantly push back on is that this is not even near done, in a bunch of ways that I’m going to get to. Self-driving is very interesting because it’s definitely where I get a lot of my intuitions because I spent five years on it. It has this entire history where the first demos of self-driving go all the way to the 1980s. You can see a demo from CMU in 1986. There’s a truck that’s driving itself on roads.
Fast forward. When I was joining Tesla, I had a very early demo of Waymo. It basically gave me a perfect drive in 2014 or something like that, so a perfect Waymo drive a decade ago. It took us around Palo Alto and so on because I had a friend who worked there. I thought it was very close and then it still took a long time. For some kinds of tasks and jobs and so on, there’s a very large demo-to-product gap where the demo is very easy, but the product is very hard. It’s especially the case in cases like self-driving where the cost of failure is too high. Many industries, tasks, and jobs maybe don’t have that property, but when you do have that property, that definitely increases the timelines. For example, in software engineering, I do think that property does exist. For a lot of vibe coding, it doesn’t. But if you’re writing actual production-grade code, that property should exist, because any kind of mistake leads to a security vulnerability or something like that. Millions and hundreds of millions of people’s personal Social Security numbers get leaked or something like that. So in software, people should be careful, kind of like in self-driving. In self-driving, if things go wrong, you might get injured. There are worse outcomes. But in software, it’s almost unbounded how terrible something could be.
I do think that they share that property. What takes the long amount of time and the way to think about it is that it’s a march of nines. Every single nine is a constant amount of work. Every single nine is the same amount of work. When you get a demo and something works 90% of the time, that’s just the first nine. Then you need the second nine, a third nine, a fourth nine, a fifth nine. While I was at Tesla for five years or so, we went through maybe three nines or two nines. I don’t know what it is, but multiple nines of iteration. There are still more nines to go.
That’s why these things take so long. It’s definitely formative for me, seeing something that was a demo. I’m very unimpressed by demos. Whenever I see demos of anything, I’m extremely unimpressed by that. If it’s a demo that someone cooked up as a showing, it’s worse. If you can interact with it, it’s a bit better. But even then, you’re not done. You need the actual product. It’s going to face all these challenges when it comes in contact with reality and all these different pockets of behavior that need patching.
We’re going to see all this stuff play out. It’s a march of nines. Each nine is constant. Demos are encouraging. It’s still a huge amount of work to do. It is [software engineering] a critical safety domain, unless you’re doing vibe coding, which is all nice and fun and so on. That’s why this also informed my timelines from that perspective.”
[Link To Interview]
It's Not Clear Scaling Laws Will Be Able to Hold
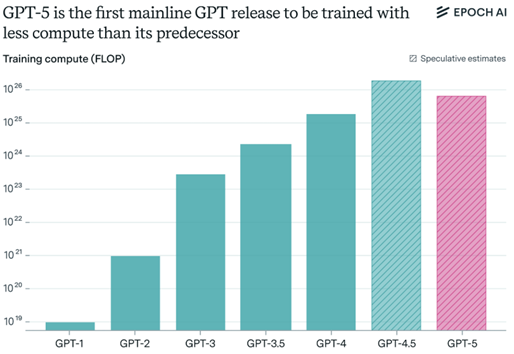
I have some concerns about the logical coherency of the “scaling law continuing to hold” argument based on the releases of GPT-4.5 & 5. While I acknowledge the ability to scale along post-training and test-time vectors, the core claim regarding pre-training scaling laws is this: more parameters, more data, more compute, better model. Credible reports[33] indicate that ChatGPT-4.5, codenamed “Orion,” was originally slated to be ChatGPT-5, but the improvements vs. GPT-4 weren’t significant enough and the model was underperforming on internal benchmarks. One of the key issues appears to be that OpenAI’s goal was to simply “build a bigger” model, but that the underwhelming results indicate that pre-training scaling laws were beginning to yield diminishing returns. In fact, GPT-5 likely used less pre-training compute (and has fewer parameters) than GPT-4.5, yet was deemed to have better performance. While optimists will point out that this highlights we are able to scale along post-training/RL and test-time compute (and I don’t disagree for the immediate future), I think it is instructive that scaling laws do not appear to be holding for the first vector (pre-training).
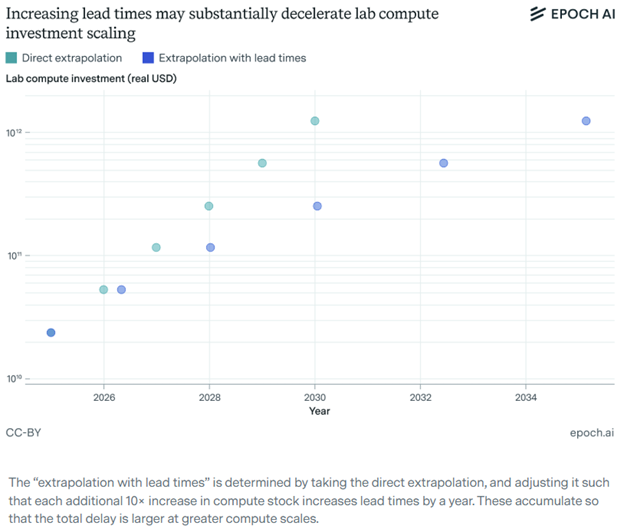
Even if scaling laws do hold theoretically, we are also approaching real-world bottlenecks. We’ve trained on virtually all of the world’s textual information, so it’s increasingly difficult to continue throwing more high-quality data at LLMs. Additionally, we’re already training models that cost hundreds of millions/billions of dollars – yet we will need to continue scaling compute by orders of magnitudes (and therefore costs by orders of magnitude, although at a slower pace due to compute efficiency gains). Increasing model parameters sizes limited GPU memory as well. And more recently, the bottleneck is increasingly power availability (see recent Jensen & Jassy comments). While there are potential solutions to some of these issues (large corpus of video data to be trained on, synthetic data, continuous computing efficiency gains, new model architectures that reduce memory needs, etc.), the fact remains that there are numerous real world bottlenecks on the horizon and it isn’t a foregone conclusion that we push past each of them without AI progress being slowed meaningfully.
Circular Financing Agreements Are Due to Legacy Cloud Providers “Pulling Back”
As highlighted above, we are beginning to see the introduction of “creative” financing arrangements such as the aforementioned agreements between OpenAI and Oracle/Nvidia/AMD. Again, the primary reason for this is that the hyperscalers have been able to fund most of the investment to-date via internal cash generation, but as we’ve moved into capacity planning for 2026/2027/2028, hyperscalers can no longer foot the bill (to the degree that will satisfy OpenAI and other frontier labs). As mentioned earlier, their cash from operations will not cover the required capex starting in 2026/2027.
It’s also worth noting that Microsoft continues to have a right-of-first-refusal with OpenAI for compute capacity through 2030. The deal Oracle signed, Microsoft turned down. Now, OpenAI can go out and get a price & spec quote from anyone and then bring it to Microsoft. So, Microsoft may have simply not liked the pricing or the specs. However, it’s likely (and supported by (i) comments Microsoft IR recently made at an investor dinner and (ii) comments made during a recent expert call by a former OpenAI employee) that Microsoft had some concerns about building 4.5 GW+ of capacity for a business (with ~2.5 GW of capacity currently) that is burning tremendous amounts of cash.
Dylan Patel summarized the current state of affairs when discussing how the OpenAI/Oracle deal came into existence on a recent a16z podcast.
“Yeah. So Microsoft was exclusive compute provider. It got re-orged to right of first refusal. And then Microsoft… Well, if OpenAI is like, “We're gonna sign a $80 billion contract or a $300 billion contract for the next five years, do you guys want it?” And they're like, “No, what?” “Okay, cool.”
And then they go to Oracle, right? OpenAI needs someone with a balance sheet to actually be able to pay for it. And then they'll make tons of money off of OpenAI on the margins, on the compute and the infra and all these things.
But someone's gotta have a balance sheet. And OpenAI doesn't have a balance sheet. Oracle does, although, given the scale of what they signed… We had also had another source of information, which was that they were talking to debt markets, right? Because Oracle actually just needs to raise debt to pay for this many GPUs over time.
Now they won't do it like immediately, like they can pay for everything this year and next year from their own cash. But like in ‘27, ‘28, ‘29, they'll start to have to use debt to pay for these GPUs, which is what, you know, CoreWeave has done. And many of the neoclouds, most of it's debt-financed. Even Meta went and got debt for their Louisiana mega data center.
… Microsoft has chickened out.” – Dylan Patel, CEO of SemiAnalysis (9/23/2025)
While “Microsoft chickening out” is one way of framing the situation, another is that Microsoft, with more insight into OpenAI than any other outside party, a host of internal AI experts, and more experience running a hyperscale cloud business than anyone else in the world besides AWS, simply said “we’re uncomfortable building this.”
To date though, it appears as if Microsoft has been overly-conservative/consistently underestimating demand. At the beginning of 2025, Microsoft management thought they’d be in a balanced supply/demand situation by June 2025. Then, they updated this timeline to year-end 2025. Now, reports indicate that management believes they’ll remain capacity-constrained well into 2026. This has provided the opportunity for companies like CoreWeave & Nebius to step in and provide capacity to both frontier labs and Microsoft itself.
However, it is worth noting that the players with the most informed view of both (i) the frontier lab product roadmap and (ii) the at-scale economics of the GPU-hyperscale business (Microsoft and Amazon) are being more measured with their capex (although still investing hundreds of billions of dollars) and are choosing to let some of this business go to neocloud competitors.
As discussed previously, this introduces the need to find other large balance sheets to fund this buildout. As of now, the likely investors appear to be infrastructure/private-credit funds such as Brookfield, Blackstone, GIP, and Apollo. I believe this introduces significantly more vulnerability into the buildout roadmap. Hyperscalers using their internal cashflow may be willing to make increasingly large bets due to (i) a desire to protect their market position and (ii) a very low implied cost of capital (opportunity cost = interest rates on cash). However, more financially oriented investors are going to (i) be unconcerned with protecting legacy market positions, (ii) have higher costs of capital, and, (iii) in my estimation, be more likely to pull back from funding AI DC investments pending a change in sentiment/narrative. I believe the AI DC buildout “baton pass” from unlevered hyperscalers to debt-financed private equity introduces significantly more fragility into the ecosystem. Put simply, the incremental leg of the datacenter buildout isn’t going to be greenlit by Jassy, Satya, and Sundar – but by Marc Rowan, Bruce Flatt, and Jon Gray. Previously, the “tech-CEO true-believers” could continue to invest in the face of a pullback in sentiment based on their internal views of continued underlying model improvement & internal use-case “fungibility.” At this stage though, with 3rd parties providing the financing, near-term revenue generation and pay-back periods will be top of mind. What then becomes the primary issue is not the continued compounding of scaling laws and fundamental model improvements, but everyone’s belief that they’re going to get paid back. The AI capex buildout is now a confidence game – and one bad model run, or a failure to find a monetization mechanism in the near term, could result in a significant pullback in planned DC investment.
Potential Model Efficiency Improvements
The “DeepSeek” moment earlier this year caused a sell-off in AI related names due to the fact that a frontier open-source model appeared to be trained at a fraction of the cost of other closed-source frontier models. This called into question the need for the amounts of compute (read: Nvidia chips) and DC capacity that forecasts had previously called for (and the frontier labs’ ability to monetize their expensive training runs). While this proved to be a false alarm, it isn’t an impossibility that a step-function improvement in model architecture could drastically reduce compute needs for the same level of performance. While the much discussed “Jevon’s paradox” argument would lead one to believe that this would eventually prove to be a positive for compute demand, it’s quite possible that this would call into question the amount of resources currently being marshalled towards building GW training clusters.
In fact, Samsung recently released a tiny reasoning model (TRM) that outperformed Gemini 2.5 and OpenAI’s o3-mini on the ARC-AGI-1 and ARC-AGI-2 benchmarks… while being ~10,000x smaller (fewer parameters). While these benchmarks are primarily visual puzzles (think Sudoku) and the use cases for this model are narrow at the moment, the implications are potentially significant.
At its core, Samsung created a reasoning model that works differently than current reasoning models. Current reasoning models (Gemini/ChatGPT) basically produce a string of tokens (words) when attempting to answer questions, and then re-feed themselves their first answer, consuming the tokens they just produced, in an attempt to reason over the output they just created. They do this repeatedly, refining the answer over many attempts. However, Samsung’s model performs a similar feat, but updates the model’s weights recursively instead of producing a new token string to be re-consumed. Some argue this is closer to how humans behave – we don’t say one thing, think about how that sounded, refine it, say it again, think about how that new phrase sounded, refine it, etc… we think about what we are going to say and update our thoughts internally (our “model weights”) before providing an answer. Samsung’s approach is significantly more compute efficient for a certain set of tasks and provides better results.
I’m not arguing that TRMs are going to cause the next market sell-off. However, I think there is a possibility that even if one is a long-term believer in Jevon’s paradox as it applies to compute, any potential reduction in perceived demand for compute is likely to present a narrative violation.
Limitations of Current Model Architecture
Many leading AI researchers have critiqued LLMs (and transformer-based models more generally) for a bevy of reasons, but most of them hone in on a similar theme – the lack of a “world model.”
Essentially, LLMs lack an understanding of how the world actually works (and their lack of memory neuters their ability to build this understanding). They are “pattern recognizers” focused on next-token prediction, but don’t have a causal, manipulable model of the world. They’ve been called “stochastic parrots”, as they simply mimic observable patterns. This is why they hallucinate, contradict themselves, and can often fail simple causal probes once a prompt deviates from a topic it has been pre-trained on. These models work incredibly well when the “problem” being presented to it is within the “distribution” of its training data. However, when presented a problem not in their pre-trained distributions, the models struggle.
While there are numerous examples of academic research probing these issues, a recent paper by Apple’s AI team (“Illusion of Thinking”) is noteworthy. Basically, the team created numerous puzzles that start simple and progressively get harder (like Tower of Hanoi or the River Crossing problem). These are ideal tests because the rules never change, only the difficulty does. If the model really “understands” the problem, it should handle tougher versions just fine. On the simpler problems, both models did fairly well. However, as the puzzles got harder, the models “collapsed” – their accuracy dropped almost to zero. In fact, the reasoning models actually gave shorter, lazier explanations when things got tough (basically giving up). Even when Apple researchers told them exactly how to solve the puzzle (gave them the algorithm), they still couldn’t apply it correctly. The takeaway is that these models don’t actually “reason.” They do a fantastic job of repeating patterns that look like thinking, but they often collapse when faced with complex tasks.
The fact that these models have no true “memory” mechanism is also a significant limiting factor. People have analogized LLMs to a goldfish with an encyclopedic memory of the world but a five-second memory of your conversation with it. It has no ability to convert conversations into long-term memory… no current mechanistic ability to update its priors (model weights) over time based on feedback/on-the-job performance. This poses a significant limitation to an LLM ever truly building a “world model,” limiting agentic flexibility and the ability for LLMs to handle multi-staged, hierarchical, or generally complicated tasks.
The Risk of Underspending
"If we end up misspending a couple of hundred billion dollars, I think that that is going to be very unfortunate, obviously… But what I'd say is I actually think the risk is higher on the other side… If you build too slowly, and superintelligence is possible…” – Mark Zuckerberg, CEO of Meta (9/18/2025)
“I think the one way I think about it is when we go through a curve like this, the risk of under-investing is dramatically greater than the risk of over-investing for us here, even in scenarios where if it turns out that we are over-investing, we clearly -- these are infrastructure which are widely useful for us. They have long useful lives, and we can apply it across, and we can work through that. But I think not investing to be at the front here, I think, definitely has much more significant downside.” – Sundar Pichai, CEO of Google (7/3/2024)
These comments need no further explanation. Almost every long-lead time capital intensive investment cycle where demand initially outstrips supply ends with supply outstripping demand. It’s capital cycle economics 101. When you have the CEOs of the most aggressive AI DC investors in the world telling you that “we’d rather overinvest,” you can be assured this will eventually end with overinvestment. The question is, are we there yet, or is that amount 5x higher from here?
Valuation – What’s Priced In?
Above, I’ve laid out some fundamental bear & bull arguments. However, even if you’re a long-term AI optimist, there is the question of “what’s priced in?” The bulls argue that, for the most part, stock price performance of the AI leaders have followed earnings (Exhibit 20), valuations are stretched but not as high as the 2000s bubble (Exhibit 21/23), and the index is now made up of higher quality constituents which justifies a higher earnings multiple (Exhibit 22).
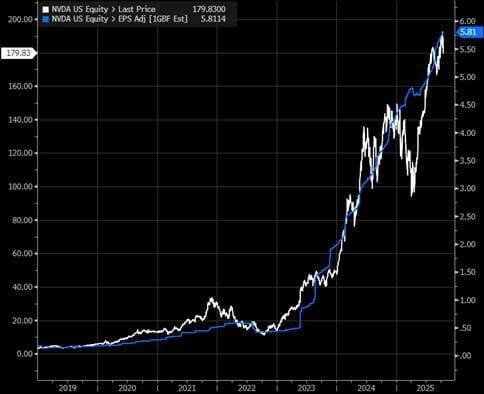
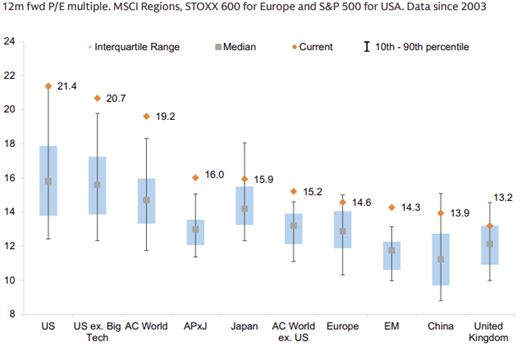
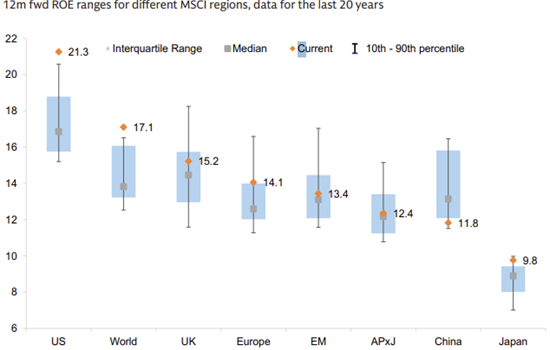
While all fair points, I believe there is an oversight that all of the above arguments fail to account for: due to the nature of DC builds there is a timing mismatch between when suppliers recognize revenue & earnings (immediately) and when buyers recognize expenses (depreciated over ~6-year useful lives). Put simply, Nvidia’s earnings keep climbing because they’re selling more GPUs, but the hyperscalers’ earnings aren’t yet impacted because the depreciation isn’t fully flowing through their income statements yet. This impacts not only the higher earnings, but also the higher ROE (as net income is used to determine ROE) being used to justify the higher multiple.
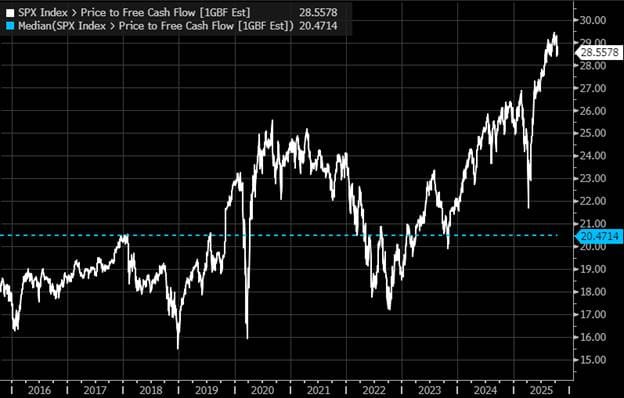
In my opinion, a better way to judge the market’s valuation is by looking at its FCF multiple (considering the large percentage of cashflow being spent on AI DCs). While the S&P 500 trades at 22.6x forward earnings (already above the 90th percentile valuation range), the S&P 500’s FCF multiple sits at 28.5x FCF (near all-time highs) – a ~26% premium to its EPS multiple. For context, the S&P 500’s median “FCF-multiple to PE-multiple” premium has been ~12% since 2015. While earnings have been marching upwards due to a timing mismatch between revenue and expense recognition, the market’s rise has significantly outpaced estimated FCF generation.
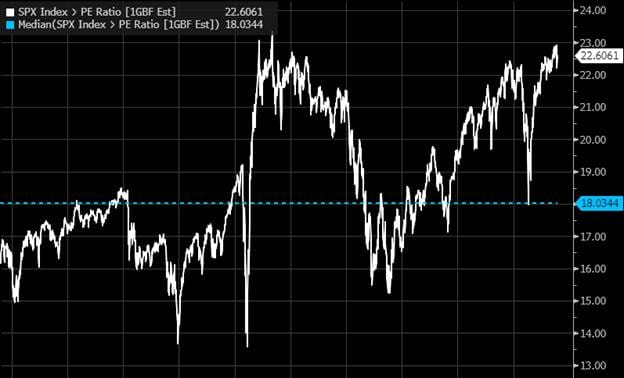
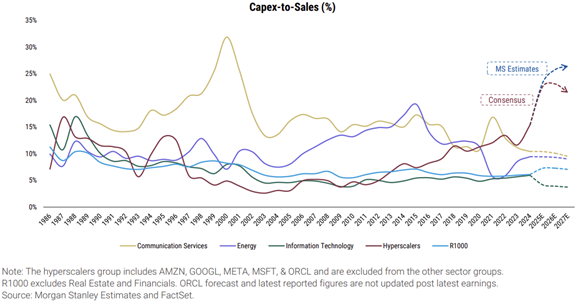
On a related note, we are starting to see capex-to-sales ratios that rival the 2000s fiber build out and the fracking boom of the mid-teens.
With that said, accounting exists for a reason. These GPUs do have useful lives, and while the capex is an upfront investment, hyperscalers and neoclouds may very well be able to rent these chips out at attractive economics over the next few years. It’s not a foregone conclusion that just because near-term FCF support is lower than normal that these assets will not start producing significant cashflow over the next few years. However, the fact remains that there is very little current cashflow supporting this market relative to any other point in history.
Other Signs of Potential Excess
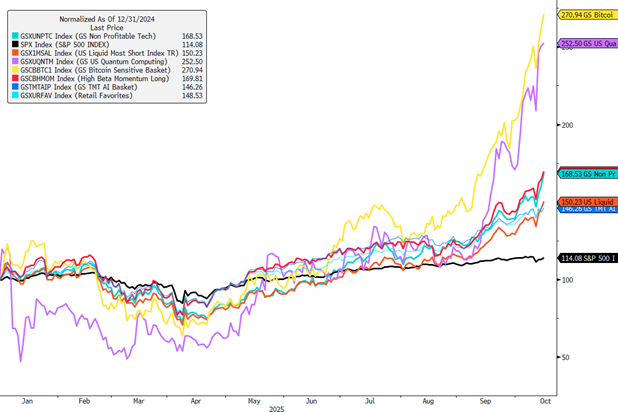
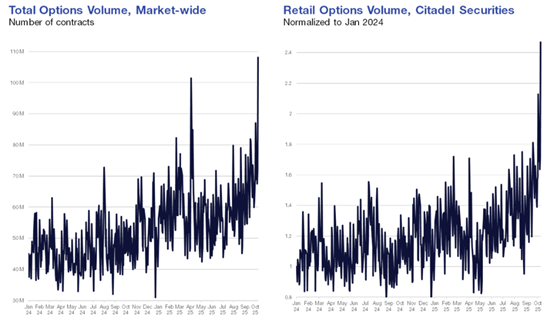
While the S&P Equal-Weight Index trades at ~17x PE (not exactly bubblish), there are signs of euphoria elsewhere in financial markets. 0DTE option volumes, retail trading activity, and narrow market leadership to name a few. For lack of better words, we’re seeing very strange price movements this year – and it feels hard to believe that a segment of the market that has been one of the largest YTD winners (“AI Exposed Stocks”) is not somewhat correlated with other heavily hyped baskets.
Price Returns (YTD as of October 15th) –
- GS Bitcoin Exposed Basket: +173%
- GS US Quantum Computing Basket: +158%
- GS High Beta Momentum Long Basket: +71%
- GS Non-Profitable Tech Basket: +69%
- GS US Liquid Most Short TR Basket: +51%
- GS US Retail Favorites Basket: +48%
- GS TMT AI Basket: +46%
- S&P 500 Index: +14%
My View
Fundamentally, I’m quite bullish. Scaling laws (appear to) continue to hold, and we’re still in the early innings of figuring out how to convert LLMs and other AI models into genuine economic leverage. Some worry we’re running out of high-quality pre-training data, but that fear feels exaggerated. Moore’s Law offers a useful analogy: it wasn’t a law of physics, Moore’s Law was the output of relentless engineering progress – each generation solving a new bottleneck in lithography, transistor design, materials, EDA tools, packaging, etc. High-quality textual data may be today’s bottleneck, but it’s unlikely to prove insurmountable. Task length is doubling roughly every seven months, and before the decade is over, we may very well have autonomous agents capable of executing well-defined projects over months, not minutes. It’s hard to overstate what that unlocks. By 2040, near-universal personal AI assistants, driverless mobility, and embodied robotics performing real physical labor are all plausible (likely?). The arc of progress here feels less like hype and more like inevitability.
With that said, from an investing perspective, the recently announced circular deals, the introduction of exotic financing agreements, elevated valuations, and recent euphoric market conditions make me cautious. While continued AI-research progress feels inevitable, these recent developments introduce fragility. The pace of continued investment will need to divorce from the pace of technological progress and become increasingly reliant on the pace of economic progress. While technologists sometimes view the two as synonyms, they are not. Setting aside technological bottlenecks, there are significant frictions that sit between technological progress and economic value-add. It will take time to determine the ideal AI monetization mechanisms, redevelop enterprise workflows to be AI native, and to solve the change management issues that are certain to plague both internal (middle-managers, less technically skilled workers) and external (government, compliance/security concerns) stakeholders. Any deviation from current expectations with respect to technological progress or the required economic proliferation of these technologies are likely to cool sentiments.
So, do I think we are in a bubble? Kind of. More directly, I think we are entering a period of over-investment that’s simultaneously occurring with elevated equity valuations. However, this isn’t “Web 3.0” in 2021 or Tulip mania in the 1630s. There is genuine economic value that is being, and will continue to be, created. In fact, I wouldn’t be surprised if AI related equities continued to move higher. I’m a pragmatist, and if I can still squint and have this level of investment potentially make sense to me, it’s hard for me to believe this is the peak, as I know some out there are significantly more optimistic than me.
Structural Insights
- The recent flurry of press releases/AI deals signals a critical inflection point: hyperscalers can no longer self-fund the pace of infrastructure growth OpenAI demands, forcing the emergence of creative, circular financing arrangements that introduce leverage and systemic fragility
- The AI buildout's economic impact is already massive – contributing ~0.1% to H1 2025 GDP growth despite representing only ~50% of projected 2028 spending levels. And by 2027 we will likely surpass every other tech-related capex boom on a percent of GDP basis (excluding the railroad buildouts of the 1800s)
- The pace of AI-research/innovation does not appear to be slowing, scaling laws appear to be holding (with some caveats), and the continued doubling in agentic task lengths potentially gives us line-of-sight to agentic AI researchers recursively self-improving by ~2030 (?)
- However, some researchers point out fundamental issues with LLM/transformer architecture that may elongate the timelines over which we can delegate complex/economically meaningful tasks to agents. Real world bottlenecks (training data, power, compute) may also elongate these timelines
- The disconnect between technological progress (remains robust) and economic value capture (which remains nascent) creates conditions for volatility. We need ~$1.1T+ of value-add by 2029 and it isn’t yet clear where that is going to come from. We need more robust monetization mechanisms
Investment Implications
- Be thoughtful as to how my current portfolio companies (and new potential investments) may express non-obvious correlations with AI DC spend
- Example: Non-obvious beneficiaries like United Rentals are likely seeing material impact, as AI DC projects are driving equipment rental utilization rates and pricing power in an otherwise weak non-residential construction environment
- Build conviction in and prepare a “shopping list” of high-quality, deeply moated, structural “accelerated compute” winners. Classic capital cycle dynamics argue that what overshoots on the upside will overshoot on the downside. Some of these I'm familiar with, some I need refreshed, and ohter I still need to perform initial primary diligence on others
- Ex: Nvidia, Broadcom, TSMC, ASML/KLAC/AMAT, Vertiv, Schneider Electric, GE Vernova, EDA Players, etc.
- Maintain a prudent approach: sidestep the most expensive/euphoric pockets, maintain exposure through less richly-valued beneficiaries, and prepare psychologically for the opportunity cost of potentially not participating in the final innings of exuberance. Fight to maintain an extended time horizon as the heightened pace of bullish news flow and the short-term returns of market darlings threaten to compress it. The FOMO will be strongest right when the consequences of succumbing will be the most dire.
“I made a lot of mistakes, but I made one real doozy. So, this is kind of a funny story, at least it is 15 years later because the pain has subsided a little. But in 1999 after Yahoo and America Online had already gone up like tenfold, I got the bright idea at Soros to short internet stocks. And I put 200 million in them in about February and by mid-March the 200 million short I had, lost $600 million on, gotten completely beat up and was down like 15 percent on the year. And I was very proud of the fact that I never had a down year, and I thought well, I’m finished.
So, the next thing that happens is I can’t remember whether I went to Silicon Valley or I talked to some 22-year-old with Asperger’s. But whoever it was, they convinced me about this new tech boom that was going to take place. So I went and hired a couple of gunslingers because we only knew about IBM and Hewlett-Packard. I needed Veritas and Verisign. I wanted the six. So, we hired this guy and we end up on the year — we had been down 15 and we ended up like 35 percent on the year. And the Nasdaq’s gone up 400 percent.
So, I’ll never forget it. January of 2000 I go into Soros’s office and I say I’m selling all the tech stocks, selling everything. This is crazy…at 104 times earnings. This is nuts. Just kind of as I explained earlier, we’re going to step aside, wait for the next fat pitch. I didn’t fire the two gunslingers. They didn’t have enough money to really hurt the fund, but they started making 3 percent a day and I’m out. It is driving me nuts. I mean their little account is like up 50 percent on the year. I think Quantum was up seven. It’s just sitting there.
So like around March I could feel it coming. I just — I had to play. I couldn’t help myself. And three times the same week I pick up a — don’t do it. Don’t do it. Anyway, I pick up the phone finally. I think I missed the top by an hour. I bought $6 billion worth of tech stocks, and in six weeks I had left Soros and I had lost $3 billion in that one play. You asked me what I learned. I didn’t learn anything. I already knew that I wasn’t supposed to do that. I was just an emotional basket case and couldn’t help myself. So, maybe I learned not to do it again, but I already knew that.” – Stanley Druckenmiller
Disclaimer: Nothing here is investment, legal, tax, or financial advice. It’s opinion for educational purposes only—not a recommendation to buy or sell any security. I may hold positions in securities mentioned and may change them at any time without notice. All discussion regarding investments is in sole reference to my personal investment accounts. Any discussion of performance refers solely to my personal investment accounts, is unaudited and incomplete, and is provided for illustration only. It is not marketing, advertising, or a solicitation for any advisory service, fund, or security. Past performance is not indicative of future results. Do your own research.